Предварительные замечания
R – это, в отличие от SPSS или Jamovi, это не программа с графическим интерфейсом (в которой пользователь работает в основном в диалоговых окнах), а, скорее, язык программирования, предназначенный для обработки данных. В силу этого он имеет свои плюсы и минусы. Стоит отметить, что работа с языком R требует освоения некоторых навыков программирования и для использования его возможностей надо потратить отдельное время на его освоение. Это не так сложно, как может показаться неискушенному в программировании читателю, но, конечно, требует отдельных усилий. Помимо этого, затруднения, в остальном R – это один из путей освоения и использования всевозможных методов обработки данных – от самых базовых до самых сложных и новых. Освоения такого языка как R позволяет работать с данными, получаемыми с помощью сложных методов, таких как ЭЭГ, МРТ, эффективно обрабатывать большие данные, использовать разнообразные методы структурного моделирования, машинного обучения и других современных подходов к анализу данных. Зная этот язык, можно самостоятельно реализовать практически любую статистическую процедуру, но далеко не всегда необходимо самому разрабатывать программу, можно воспользоваться готовыми решениями, созданными сообществом и распространяемыми в форме пакетов (packages) [1] . R стал одним из стандартных инструментов в обработке данных психологических исследований, знание такого языка[2] – один из востребованных навыков психолога-исследователя. Можно отметить, что в SPSS довольно давно, начиная с 16 версии, добавлен модуль интеграции с R, то есть его можно использовать и при работе в SPSS, а Jamovi изначально интегрирован с R – в нём есть модули, позволяющие переводить команды в этот язык и наоборот, выполнять команды R. Таким образом, затраты сил и времени при обучении R могут быть хорошим вложением для тех, кто планирует в будущем активно заниматься анализом данных, полученных ли в психологических исследованиях, или любых других. Эта задача для заинтересованного читателя облегчается тем, что в настоящее время существует множество ресурсов – учебников, интерактивных видеокурсов, посвященного работе с R, как для начинающих, так и для более «продвинутых» пользователей. Вот некоторые из них:
- А.Б. Шипунов, Е.М. Балдин, П.А. Волкова и др.: Наглядная статистика. Используем R! (ISBN: 978-5-97060-094-8), бесплатная электронная версия передана в общественное достояние.
- Мастицкий С.Э., Шитиков В.К.: Статистический анализ и визуализация данных с помощью R (ISBN: 978-5-97060-301-7) (бесплатная электронная версия)
- Роберт И. Кабаков «R в действии. Анализ и визуализация данных на языке R»
Также можно порекомендовать видеокурсы для начинающих.
На русском языке:
На английском языке:
- Coursera: R Programming(входит в специализацию Data Science)
- Data Camp: Introduction to R
- Udemy: R Programming A-Z™: R For Data Science With Real Exercises (см. также другие курсы в разделе R)
В рамках нашего учебника мы не ставим задачу обучения работы с R, однако, чтобы читатель, который еще не знаком с R, но хочет освоить его и потренироваться на предлагаемых нами упражнениях и заданиях, мог это сделать, остановимся на базовых элементах интерфейса одной из самых распространённых оболочек для работы с языком R – Rstudio и очень коротко опишем логику этого языка.
Установка программ
R и Rstudio – свободно распространяемые бесплатные программные продукты. Скачать и установить их можно с соответствующих сайтов: официальный сайт R — https://cran.r-project.org, сайт Rstudio — https://www.rstudio.com/products/rstudio/. Обе системы кроссплатформенные, можно выбрать версию под установленную на компьютере систему. Рекомендуется сначала поставить R, а затем – Rstudio, в таком случае Rstudio автоматически будет использовать установленную ранее версию базового пакета R. Также есть онлайн-версия Rstudio, доступная по адресу https://rstudio.cloud/.
Интерфейс Rstudio
При запуске Rstudio открывается графический интерфейс, изображенный на рис. П1.3(1), разбитый на 4 области[3]:
- Область записи программ (или скриптов, в дальнейшим мы будем пользоваться этим термином) – в ней отображаются созданные или открытые пользователем файлы, содержащие команды языка.
- Консоль – командная строка, в которую можно вводить команды для непосредственного их выполнения. Также в консоли отображается весь текстовый вывод результатов команд. Также переключившись во вкладку Terminal можно перейти в режим системной командной строки и выполнять команды установленной оперативной системы. На вкладке Jobs отображается процесс выполнения программ (в некоторых случаях оно может быть достаточно длительным, но в рамках рассматриваемых нами примеров расчёты и обработка данных будет занимать доли секунды).
- Область, в которой по умолчанию скрыт список файлов текущей папки (её можно изменять). Обратите внимание, что при загрузки файлов данных в R необходимо, чтобы либо они были расположены в текущей рабочей папке, либо указывать полный путь к файлу[4]. Также в этой области есть важные вкладки: Plots – на ней будут отображаться графики и диаграммы; Packages – окно управления пакетами расширений (см. о пакетах ниже); Help – окно справки; Viewer – окно, в котором отображается форматированный вывод некоторых специальных команд.
- Область, в которой по умолчанию отображаются все объекты, загруженные в рабочее пространство – переменные, наборы данных, объекты языка R и др. Также в этой области есть вкладки: History, содержащая историю команд; Connections – интерфейс для связи со внешними базами данных; Tutorials – окно, в котором можно вызвать и пройти несколько обучающих интерактивных уроков по базовым функциям R (требует установки дополнительного пакета learnr).
 Рисунок П1.3(1). Общий вид интерфейса Rstudio.
Рисунок П1.3(1). Общий вид интерфейса Rstudio.
Общие принципы работы в R
Работа в R заключается в написании и выполнении набора команд, которые позволяют проводить различные операции и процедуры статистической обработки данных. Выполнить команду можно двумя способами: ввести её в консоль (2) и нажать Enter или набрать в окне скрипта (1) и затем для выполнения нажать сочетание клавиш ctrl-Enter или кнопку Run в верхнем правом углу этой области (в этом случае выполняется текущая строка, в которой стоит курсор или выделенный фрагмент). В качестве примера выполним простейшую команду: сложим два числа — 4 и 5 и присвоим результату имя x, создав таким образом переменную[5] результат сложения двух чисел – 4 и 5, что на языке R выглядит так:
x <- 4 + 5
Знак <- в R означает присваивание (в других языках для этого чаще используется знак равенства (=), в R его тоже можно использовать, но <- более корректен и имеет некоторые дополнительные преимущества в сложных скриптах (в Rstudio он может быть введен сочетанием клавиш alt-‘-‘). Введя эту команду в консоль и нажав Enter вы выполните операцию сложения чисел 4 и 5 и присвоите результату имя x (можно также сказать, что вы создадите переменную, содержащую результат операции). Чтобы вывести на экран содержимое, обозначенное переменной x (и любого другого загруженного объекта в R) можно просто набрать её имя в консоли и нажать Enter.
Если результат операций не связываать с переменной, то результат будет непосредственно отображён в консоли. В дальнейшем мы рекомендуем мелкие текущие расчеты делать непосредственно в консоли, а более существенные команды, относящиеся к анализу данных, записывать в скрипте и выполнять оттуда нажатием ctrl-Enter или кнопки run. Такие наборы команд – скрипты – можно сохранять и впоследствии вызывать, дополнять, воспроизводя и продолжая анализ. Имена переменных могут содержать любые (строчные и прописные) буквы и цифры, а также точки и знаки нижнего подчёркивания. Нельзя начинать имена переменных с цифр, также не рекомендуется использовать символы не латинского алфавита (технически R позволяет использовать в именах переменных любые буквы, например, кириллицу, но такие переменные могут вызвать ошибки при использовании некоторых функций). Также заметим, что в R заглавные и строчные буквы различаются системой и, например, переменные data и Data будут интерпретироваться как два разных объекта, то же касается и любых команд.
Упражнение П1.3(2). Рассчитайте, не сохраняя результат в переменную значение произведения 16*16, проверьте, что результат будет тем же, если дать команду расчета 16 во второй степени (16^2). Создайте новую переменную y, в которую поместите результат деления 512 на 16 и переменную z, в которую поместите результат разности чисел 324 и 167.
Объекты в R можно комбинировать друг с другом, например, если после выполнения упражнения П1.3(2) дать команду y+z, то будет рассчитана сумма этих переменных.
Основные типы переменных
В R есть много различных типов переменных, пока мы имели дело с числовыми переменными, имеющими только один элемент. Отметим, что переменные могут содержать не только числовые данные, но и данные другого типа: логические (истина/ложь, в языке R – TRUE и FALSE), текстовые и др. Также переменная может содержать не один, а множество элементов, и в зависимости от их организации относиться к разным типам. Перечислим некоторые типы переменных, которые могут быть нам полезны в дальнейшем.
Вектор (vector) – набор однородных (логических, числовых или текстовых) элементов. Задать такую переменную можно командой c (от conjunction). Например, команда
a <- c(1, 2, 4, 1024)
создаёт вектор из четырех чисел и помещает его в переменную a. Если нужно обратиться не ко всему вектору целиком, а к его элементу, то его номер задаётся в квадратных скобках, например, a[3] – это обращение в 3 элементу («4»).
Матрица (matrix) – двухмерная таблица, состоящая из однородных элементов. Задаётся командой matrix, имеющая три обязательных аргумента – набор данных (в виде вектора), число строк и число столбцов. Например, команда
b <- matrix(c(1,2,3,4,5,6,7,8), 2, 4)
создаёт матрицу из 2 строк и 4 столбцов, содержащей числа от 1 до 8 (вектор по умолчанию раскладывается по столбцам)[6]. Чтобы обратиться к элементу матрицы, необходимо в квадратных скобках указать номер строки и номер столбца элемента, например, b[2, 3]обращается к элементу во второй строке третьего столбца созданной матрицы («6»). Также можно задавать диапазон элементов, указывая номер первого и последнего, разделенные двоеточием (напримерb[1:2, 1]обращается к первым двум строкам первого столбца) или сразу весть столбец или всю строку, пропустив первый или второй индекс соответственно (например,b[ ,1]обращается ко всему первому столбцу, аb[2,]– ко всей второй строке).
Таблица данных (data frame) – таблица, содержащая переменные-столбцы, которые могут быть разного типа – логические, числовые, текстовые, факторы и др. Это распространенный формат данных, в удобно хранить результаты психологических исследований, содержащих разнообразные сведения об испытуемых и респондентах, и именно с ним мы будем работать в дальнейшем. Оговоримся, что следует различать переменные как объекты языка R и переменные-столбцы таблицы. В дальнейшем в неочевидных случаях мы будем пояснять о «переменной» какого типа идёт речь. Создать таблицу данных можно с помощью командыdata.frame(). Например, следующая команда
df <- data.frame(var1=c("a", "b", "c", "d"), var2 = c(1, 2, 3, 4), var3 = factor(c(1, 1, 2, 2), labels = c("male", "female")))
создаёт таблицу, содержащую три переменные – var1 – текстовую, var2 – числовую, var3 – фактор с двумя уровнями male (мужчина) и female (женщина). Чтобы обратиться к переменной можно либо указать номер столбца (df[ ,1] вызывает первый столбец), либо прямо указать имя переменной, предварив его знаком $ (df$var1 вызывает тот же первый столбец). Также как и в векторах или матрицах, можно выбирать отдельные элементы переменной (например,df$var1[1:2]выбирает первые два элемента переменной var1).
Отдельно укажем, что можно выбирать элементы по условию. Например, команда df$var1[df$var3 == "male"][7] выберет только те элементы var1, которые соответствуют строкам со значением male в факторе var3.
Список (list) – набор разнородных объектов, которые могут любыми – числами, символами, матрицами, векторами и т.п. Это может быть удобно, если надо компактно записать и сохранить разнородные данные. Например, выполнение многих функций в R могут быть сохранены в виде таких списков, содержащих самые резные результаты расчётов. Создать список можно с помощью функцииlist. Например, команда
my_list <- list(x = "My list", y = c(5, 1, 3), z=matrix(c(1:8), 2, 4))
создаёт список из трех элементов – строковой переменной x, числового вектора y и матрицы z. Обратиться к элементу списка можно также как в таблице данных, использовав знак $ и имя элемента или указав его порядковый номер в двойных квадратных скобках. Например, командыmy_list$xиmy_list[[1]]вызовут первый элемент списка x. Если надо обратиться к какой-то части элемента, можно указать номер (или диапазон) этой части. Например, командаmy_list[[2]][3]обратиться к третьему элементу вектора y, а командаmy_list[[3]][2,]выведет целиком вторую строку матрицы z.
На этом мы закончим крайне краткое описание структуры переменных и перейдём к вопросу ввода или чтения данных в R.
Ввод, чтение и запись данных в R
Пример П1.3(3). Организация ввода данных исследования в R
Проведено тестирование уровня ситуативной и личностной тревожности 10 студентов (5 мужчин и 5 женщин). В результате тестирования у каждого испытуемого был рассчитан итоговый балл ситуативной и личностной тревожности. Чем выше балл, тем более выражен тот или иной вид тревожности, максимально возможный балл равнялся 30. Также исследователи регистрировали пол и возраст испытуемых. Помимо этого, студентам задавался следующий вопрос: «Насколько часто Вы волнуетесь перед экзаменами?». Испытуемые должны были обвести один из вариантов ответа: «Почти никогда», «Редко», «Иногда», «Часто/почти всегда».
Полученные в ходе исследования результаты представлены в таблице П1.3(4).
Таблица П1.3(4). Данные исследования личностной и ситуативной тревожности.
| № | Имя | Пол | Возраст | Ответ на вопрос “Как часто я волнуюсь перед экзаменом?” | Ситуативная тревожность | Личностная тревожность |
| 1 | Н.И. | Женский | 20 | Часто/почти всегда | 20 | 26 |
| 2 | К.Л. | Мужской | 18 | Почти никогда | 18 | 16 |
| 3 | П.Д. | Мужской | 18 | Иногда | 15 | 20 |
| 4 | У.Р. | Женский | 18 | Часто/почти всегда | 17 | 21 |
| 5 | И.К. | Мужской | 19 | Редко | 19 | 17 |
| 6 | Т.К. | Женский | 20 | Редко | 17 | 18 |
| 7 | А.Н. | Женский | 21 | Иногда | 21 | 19 |
| 8 | Г.М. | Мужской | 21 | Почти никогда | 10 | 19 |
| 9 | В.Н. | Женский | 19 | Иногда | 19 | 18 |
| 10 | Л.Н. | Мужской | 20 | Иногда | 20 | 20 |
Рассмотрим, как корректно ввести полученные результаты в R. Сразу заметим, что в рамках нашего учебника почти все наборы данных в примерах уже оформлены так, что могут быть импортированы и готовы к статистической обработке, но в рамках данного введения один раз подробно рассмотрим, как можно оформить таблицу данных «с нуля». Если читателю покажется это описание слишком сложным для начала, его можно пропустить и перейти сразу к описанию загрузки готовых таблиц данных.
Один из вариантов оформления данных – это создание векторов, соответствующих переменным и последующее объединение этих векторов в единую таблицу.
Первая, служебная переменная – номер испытуемого представляет собой числовой ряд от 1 до 10 и может быть кратко задана так[8]:
num <- c(1:10)
Вторая переменная – инициалы испытуемых, текстовая, её можно ввести следующим образом:
names <- c("Н.И.", "К.Л.", "П.Д.", "У.Р.", "И.К.", "Т.К.", "А.Н.", "Г.М.", "В.Н.", "Л.Н.")
Переменную, обозначающую пол, удобно задать как фактор, обозначив единицей мужчин, а двойкой – женщин:
gender <- factor(c(2, 1, 1, 2, 1, 2, 2, 1, 2, 1), labels = c("Мужской", "Женский"))
Возраст – это простая числовая переменная:
age <- c(20, 18, 18, 18, 19, 20, 21, 21, 19, 20)
Ответ на вопрос представляет собой порядковую шкалу[9], и её в R корректно задать как фактор, аналогично полу, пронумеровав варианты ответа от «никогда» до «часто/почти всегда):
question <- factor(c(4, 1, 3, 4, 2, 2, 3, 1, 3, 3), labels = c("Почти никогда", "Редко", "Иногда", "Часто/почти всегда"))
Наконец, показатели двух типов тревожности представляют собой две числовые переменные:
anx_sit <- c(20, 18, 15, 17, 19, 17, 21, 10, 19, 20) anx_pers <- c(26, 16, 20, 21, 17, 18, 19, 19, 18, 20)
Теперь, когда все переменные заданы в виде отдельных векторов, можно их объединить в единую таблицу данных:
anx_table <- data.frame(num, gender, age, question, anx_sit, anx_pers)
Просмотреть сформированную таблицу можно с помощью функции View:
View(anx_table)
Все эти команды сохранены в скрипте appendix1_3.R. Для их выполнения можно вызвать этот файл в Rstudio и, выделив нужные команды, запустить их.
Другой вариант загрузки данных в рабочее пространство R, который на практике используется намного чаще, и которым мы будем пользоваться в дальнейшем – это загрузка таблиц данных, сохраненных в одном из распространенных форматов.
В базовой комплектации R таким форматом является, прежде всего, csv (comma-separated values), который представляет собой текстовые таблицы, в которых знаком разделителей столбцов данных служат запятые. Данные Соответствующему нашему примеру в формате csv хранятся в файле example_p3_1.csv. Если его открыть в любом текстовом блокноте, то можно увидеть его содержимое, соответствующее исходной таблице выше. Для того чтобы прочесть такой файл в R, можно использовать командуread.csv, указав в качестве обязательного аргумента имя файла (с путем к нему, если он расположен не в рабочей папке)[10]. Попробуйте скачать файл в рабочую папку и загрузить эту таблицу в переменную anx_table_csv с помощью команды
anx_table_csv <- read.csv("example_p3_1.csv")
При этом обратите внимание, что переменные в новой таблице anx_table_csv данных только двух типов – числовой или текстовый. Таким образом, для корректной работы с данными требуется дополнительно преобразовать переменные в факторы, указать значения их уровней и т.п. Такая первичная обработка данных – это отдельная тема, мы для удобства будем использовать в дальнейшем формат данных sav, который является основным для статистического пакета SPSS, R при установке дополнительного пакета позволяет считывать и записывать данные в этом формате. Для записи можно использовать возможности пакета haven, а для чтения – функции пакета foreign. Для их установки необходимо на подключенном к интернету компьютере выполнить команду[11]
install.packages(c("haven", "foreign"))
После установки пакеты будут доступны и должны быть загружены в рабочее пространство с помощью команд require или library (подробнее о различиях между этими функциями см. https://www.r-bloggers.com/2016/12/difference-between-library-and-require-in-r/):
library("haven")
library("foreign")
Теперь в рабочем пространстве становятся доступны функции этих пакетов, в частности,write_savиз пакета haven для записи иread.spssиз пакета foreign для чтения файлов в формате sav.
Записать таблицу в формате sav можно командой write_sav, указав в качестве аргументов имя таблицы и имя файла:
write_sav(anx_table, "anx_table.sav")
Считать же файл в таблицу данных удобнее всего командой read.spss, при этом помимо обязательного имени файла (с полным путём, в случае, если он не сохранён в рабочей папке) стоит указать качестве дополнительных аргументов кодировку файлов, например, reencode=»utf-8″ (именно в этой кодировке по умолчанию сохраняет файлы данных SPSS и функция write_sav) и формат создаваемого объекта – to.data.frame = TRUE (иначе, по умолчанию, данные считываются в формате списка). Результат надо поместить в новую переменную:
anx_table_new <- read.spss("anx_table.sav", reencode = "utf-8", to.data.frame = T)
Далее, мы предлагаем читателю самостоятельно выполнить задание, подобное описанному выше.
Упражнение П1.3(5). В таблице П1.3(6) представлены показатели эмоционального интеллекта в трех группах испытуемых (будем считать, что это интервальная шкала). Введите результаты эксперимента в R (название таблицы данных можно придумать самостоятельно), а затем сохранить эту таблицу в формате sav под любым понятным именем.
Таблица П1.1(6). Данные исследования эмоционального интеллекта у испытуемых с истерическим расстройством
| Номер испытуемого | Балл по шкале «Эмоциональная осведомленность» | Балл по шкале «Распознавание эмоций других людей» |
| Здоровые испытуемые | ||
| 1 | 4 | 6 |
| 2 | 6 | 5 |
| 3 | 6 | 3 |
| 4 | 3 | 2 |
| 5 | 4 | 2 |
| Испытуемые с истерическим расстройством | ||
| 6 | 6 | 5 |
| 7 | 7 | 4 |
| 8 | 3 | 5 |
| 9 | 4 | 6 |
| 10 | 3 | 5 |
| Испытуемые с шизодидным расстройством | ||
| 11 | 3 | 4 |
| 12 | 5 | 2 |
| 13 | 2 | 5 |
| 14 | 6 | 3 |
| 15 | 2 | 4 |
Основы статистической обработки в R
После ввода или чтения данных мы можем приступить к их статистическому анализу. Опишем общую схему проведения такого анализа в R. Этот язык позволяет проводить самые различные статистические процедуры и расчёты с помощью имеющихся в базовом наборе команд, а также дополнительных возможностей, предоставляемых дополнительными пакетами. В рамках нашего краткого введения мы опишем некоторые самые элементарные процедуры, а затем, по мере рассмотрения различных тем, будем включать в описание другие необходимые функции. Таким образом, основной целью этого приложения является описание техники проведения статистического анализа в R в самом общем виде на материале простого примера.
Пример П1.3(7). Процедура статистического анализа в R
Рассмотрим общую схему процедуры статистического анализа в R на простом примере — расчете средних значений и стандартного отклонения переменной. В качестве материала мы возьмем данные исследования скорости письма у детей-билингвов младшего школьного возраста. Мы предлагали второклассникам, учащимся в Финско-русской школе города Хельсинки, переписать два небольших текста — один на русском, второй на финском языках[12]. Процесс письма регистрировался с помощью графического планшета и затем подвергался обработке и анализу. В частности, оценивалась скорость письма на двух языках, основным показателем было среднее время, затрачиваемое ребенком на написание одной буквы текста. Результаты этого исследования содержатся в файле WritingBilingual.sav. Каждый испытуемый в этом наборе данных характеризуется четырьмя параметрами: идентификационным номером (переменная id), доминантностью русского или финского языка (в зависимости от основного «домашнего» языка, используемого в семье, переменная group), средним временем написания буквы на русском и на финском языках (переменные WritingLetRus и WritingLetFin соответственно). Для загрузки этого файла в R надо скачать его в рабочую папку (или в любую другую, но в этом случае надо будет указать полный путь к нему), а затем считать его в переменную, которую мы назовём data_bilingual:
data_bilingual <- read.spss("WritingBilingual.sav", reencode = "utf-8", to.data.frame = T)
Первая задача, которую можно решить с помощью R — это расчет описательной статистики[13] времени, затрачиваемого на письмо одной буквы на двух языках. Для этого можно использовать функции mean (для расчета среднего арифметического) и sd (для расчет стандартного отклонения). В качестве аргументов надо указать анализируемые переменные (имена переменных в таблице данных отделяются от имени таблицы знаком $). Команда
mean(data_bilingual$WritingLetRus)
выведет среднее время написания одной буквы на русском (3931.036 мс), а команда
sd(data_bilingual$WritingLetRus)
стандартное отклонение этого параметра (925.4401 мс).
Упражнение П1.3(8). Рассчитайте среднее и стандартное отклонение времени написания одной буквы на финском языке (переменной WritingLetFin).
Если нас интересует сравнение средних значений времени написания букв на двух языках у детей с разными доминантными языками и мы хотим оценить, насколько доминантность языка влияет на скорость письма, задача несколько усложняется. Есть несколько способов её решения, мы предлагаем использовать функциюdescribeByиз пакета psych (это очень полезный пакет, разработанный специально для обработки данных психологических исследований). Установим и загрузим его в рабочее пространство[14]:
install.packages("psych") # эту команду требуется выполнить только один раз
require("psych")
После этого можно использовать командуdescribeBy, указав в качестве первого аргумента те переменные таблицы данных, для которых должна быть рассчитана описательная статистика (зависимые переменные, в нашем примере это среднее время написания буквы на русском и финском языках), а в качестве второго аргумента group – группирующую переменную, в которой содержится информации о принадлежности испытуемого к той или иной группе (в нашем случае это переменная group). Значения группирующих и других так называемых независимых переменных так или иначе контролируются исследователем при организации и проведении исследования. В данном случае мы отбирали детей таким образом, чтобы среди них было примерно равное число детей с доминантным русским и финским языками. Например, для расчета описательной статистики времени написания буквы на русском языке нужно дать следующую команду:
describeBy(data_bilingual$WritingLetRus, group = data_bilingual$group)
После выполнения этой команды в консоли будет отображен следующий результат:
group: Russian dominant biliguals vars n mean sd median trimmed mad min max range skew kurtosis se X1 1 16 3530.67 862.1 3422.22 3490.88 807.51 2114.35 5504.02 3389.67 0.47 -0.35 215.52 ------------------------------------------------------------------------------------- group: Finish dominant biliguals vars n mean sd median trimmed mad min max range skew kurtosis se X1 1 15 4358.1 812.6 4569.25 4337.22 770.21 2914.06 6073.55 3159.49 0.07 -0.55 209.81
Как видно, этот результат намного более подробный и сложнее организован, чем в элементарных функциях mean и sd. Помимо среднего и стандартного отклонения функция рассчитывает и другие описательные статистики – медиану (median), минимум (min), максимум (max), размах (range), асимметрию (skew), эксцесс (kurtosis), стандартную ошибку среднего (se) и другие. Мы не будем подробно разбирать все выводимые результаты, остановимся на столбцах mean (среднее) и sd (стандартное отклонение). Если сравнить две группы, то можно заметить, что между группами имеются различия в скорости письма – среднее время при написании одной буквы на русском языке у русско-доминантных билингвов меньше, чем у финско-доминантных.
Упражнение П1.3(9). Проведите аналогичное сравнение среднего времени написания буквы на финском языке в двух группах испытуемых. Какая из групп билингвов пишут быстрее на финском?
Примечание П1.3(10). При желании, для более компактного представления данных, можно рассчитывать статистику не для одной, а для двух и более зависимых переменных. Для этого можно использовать так называемые формулы, которые в R устроены в общем виде следующим образом: Зависимая переменная ~ Независимая переменная. При этом если зависимых или независимых переменных больше одной, то их можно объединять знаком сложения (+). Соответственно, для наших данных можно написать общую формулу WritingLetRus + WritingLetFin ~ group, при этом, чтобы не прописывать многократно указание на таблицу данных data_bilingual, можно указать её один раз как аргумент под названием data – система будет искать эти переменные именно в этом наборе данных. Таким образом, команда для одновременного вычисления описательных статистик для обеих зависимых переменных в двух группах может выглядеть так:
describeBy(WritingLetRus + WritingLetFin ~ group, data = data_bilingual)
Результат будет таким:
group: Russian dominant biliguals
vars n mean sd median trimmed mad min max range skew kurtosis se
WritingLetRus 1 16 3530.67 862.1 3422.22 3490.88 807.51 2114.35 5504.02 3389.67 0.47 -0.35 215.52
WritingLetFin 2 16 2533.73 624.6 2528.22 2532.34 471.55 1395.96 3691.02 2295.06 -0.07 -0.81 156.15
-------------------------------------------------------------------------------------
group: Finish dominant biliguals
vars n mean sd median trimmed mad min max range skew kurtosis se
WritingLetRus 1 15 4358.10 812.60 4569.25 4337.22 770.21 2914.06 6073.55 3159.49 0.07 -0.55 209.81
WritingLetFin 2 15 2751.94 814.11 2744.23 2736.55 650.97 1355.46 4348.59 2993.12 0.44 -0.43 210.20
Графическое отображение данных
Еще один важный аспект анализа данных, на котором нужно остановиться, описывая основные функции R — это визуализация данных, их графическое отображение. В R есть несколько систем, позволяющих строить самые разнообразные график – базовая графика, пакеты ggplot2, lattice и другие. Их подробное изучение требует отдельных времени и усилий, из экономии времени мы постепенно будем вводить разные типы графиков с соответствующими пояснениями. В рамках этого краткого введения мы опишем построение графика, отображающего соотношение распределений зависимых переменных в двух группах испытуемых с помощью базовой функции boxplot , а затем более сложный пример построения столбчатого графика средних с помощью функции error.bars.byиз пакета psych.
График типа boxplot отображают распределение того или иного параметра (на русский это название переводится как «ящичные диаграммы», «ящики с усами» или просто транслитерируется как «боксплот»). Нарисуем такое распределение для времени написания буквы на русском для двух групп испытуемых и рассмотрим подобнее этот график. Для этого можно использовать функцию boxplot, в аргумент которой следует вставить формулу вида ИмяЗависимойПеременной ~ ИмяНезависимойПеременной. Соответственно, для нашей задачи эта формула будетdata_bilingual$WritingLetRus ~ data_bilingual$group.
boxplot(data_bilingual$WritingLetRus ~ data_bilingual$group)
В результате будет нарисован следующий график:
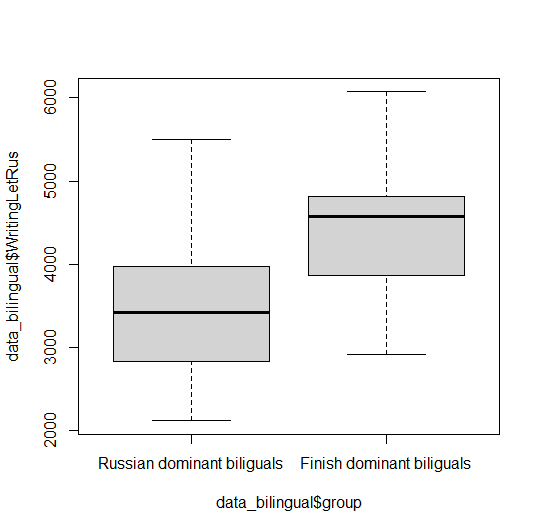 Рисунок П1.3(11). Ящичная диаграмма времени написания одной буквы на русском в двух группах билингвов.
Рисунок П1.3(11). Ящичная диаграмма времени написания одной буквы на русском в двух группах билингвов.
На графиках такого типа средняя линия – это медианное значение оцениваемого параметра, нижняя и верхняя границы «ящиков» – это первый и третий квартиль распределения соответственно. Границы усов ограничивают примерно 95% значений выборки и вычисляются следующим образом. Нижняя граница – это наибольшее значение из двух – либо минимальное значение параметра в выборке, либо разность первого квартиля и полутора межквартильных размахов (Q3-Q1). Верхняя граница – это наименьшее из двух – либо выборочный максимум, либо сумма третьего квартиля и полутора межквартильных размахов[15]. Мы не будем здесь подробно останавливаться на обосновании таких границ, но есть основания считать выборочные значения, выходящие за границы таким образом вычисленных «усов», аномально низкими или высокими и рассматривать их как выбросы. В нашем случае выбросов не наблюдается и также видно, что медианное значение оцениваемого параметра выше в группе финско-доминантных билингвов.
Упражнение П1.3(12). Постройте аналогичный график для переменной WritingLetFin. Соотнесите полученный результат с результатами функции describeBy, полученными в упражнении П1.3(9).
Теперь построим более сложный график, на котором будут отображены средние значения времени написания букв отдельно для каждого из языков и в каждой из групп. Это можно сделать разными способами, мы предлагаем использовать функцию пакета psych error.bars.by и построить с её помощью столбиковую диаграмму средних. Эта функция имеет множество параметров, позволяющих настроить отображение и оформление графика, мы приводим вариант её вызова для построения уже достаточно хорошо оформленного графика и затем поясним используемые параметры:
require("psych") #требуется, если пакет psych не загружен ранее
error.bars.by(WritingLetRus + WritingLetFin ~ group, data=data_bilingual, bars = TRUE, legend = 7, v.labels = levels(data_bilingual$group),labels = c("Russian", "Finnish"), colors = c("black", "grey"), ylim = c(0, 6000), xlab = "Language", ylab = "Mean duration of writing a letter", main = "Mean duration of writing a letter")
В аргументах функции указано следующее:
- WritingLetRus + WritingLetFin ~ group – формула переменных, используемых в графики: две зависимые переменные (время написания буквы на русском и на финском языках) ~ зависимая переменна (группа);
- data=data_bilingual – название таблицы данных, с которой мы работаем;
- bars = TRUE – указание, что нужно построить столбчатую диаграмму;
- legend = 7 – указание, что нужно вывести легенду в правом верхнем углу графика;
- labels = levels(data_bilingual$group) – подписи легенды – уровни фактора group;
- labels = c(«Russian», «Finnish») – подписи значений оси X;
- colors = c(«black», «grey») – цвета столбиков;
- ylim = c(0, 6000) – границы оси Y;
- xlab = «Language» – название оси X;
- ylab = «Mean duration of writing a letter» – название оси Y;
- main = «mean duration of writing a letter» – заголовок графика.
Более подробно об этих и других параметрах функции можно узнать из документации, для её получения можно дать командуhelp(error.bars.by)[16], после этого во вкладке help в Rstudio отобразится подробное описание функции.
Результат выполнения этой команды приведен на рисунке П1.3(14).
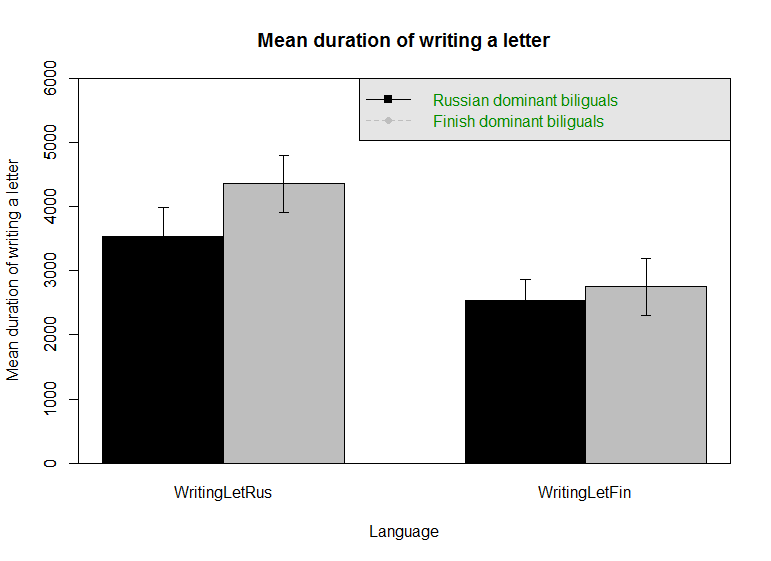 Рис. П1.3(13). Средние значения времени написания одной буквы на русском и финском языках в двух группах испытуемых.
Рис. П1.3(13). Средние значения времени написания одной буквы на русском и финском языках в двух группах испытуемых.
Как видно из графика (он отображает уже полученные нами результаты расчета описательной статистики) при письме на русском дети с доминантным русским языком пишут заметно быстрее свои сверстников с доминантным финским языком. При этом на финском в целом все дети пишут быстрее, а различия между группами незначительны. Вертикальные столбики ошибок отображают 95% доверительный интервал средних, подробнее об этом см. главу 5.
Преобразование переменных в таблице данных
В заключение нашего краткого введения укажем, что переменные в таблицах данных можно преобразовывать и рассчитывать новые данные на основе уже имеющихся. С числовыми переменными можно проводить стандартные арифметические операции – прибавлять и отнимать константу, делить и умножать на константу. Например, для перевода шкалы миллисекунд в секунды можно переменную времени разделить на 1000:
data_bilingual$WritingLetRus_sec <- data_bilingual$WritingLetRus / 1000
Также можно складывать, вычитать, умножать и делить переменные друг на друга, это делается также естественным образом. Скажем, если нам необходимо рассчитать разность времени написания одной буквы на русском и финском языке для каждого участника исследования, это можно сделать так:
data_bilingual$diffWritingLet <- data_bilingual$WritingLetRus - data_bilingual$WritingLetFin
Пропущенные значения в R
При проведении реального исследования достаточно чаcто возникает ситуация, когда у некоторых испытуемых по отдельным показателям не хватает данных и тогда в итоговой таблице данных появляются пропущенные значения (как правило, в исходных данных они либо просто отсутствуют, либо обзначаются каким-либо легко узнаваемым кодом). В R такие пропущенные значения кодируются специальным значением NA (от not available). Разные функции по-разному обрабатывают данные с такими пропущенными значениями.
Пример П.1.3(14). В файле rt_example.sav приведены модельные результаты гипотетического исследования влияния утомления на время реакции у взрослых испытуемых. Первая переменная — gender — содержит информацию о поле испытуемого, вторая переменная — rt1 — фоновое время простой зрительно-моторной реакции в мс, а третья — rt2 — время реакции в такой же задаче, но после выполнения монотонной работы (например, выполнения корректурной пробы). После загрузки данных проверить таблицу на наличие пропущенных значений можно, в частности, с помощью функции summary. Выполнение команд
require("foreign")
data_rt <- read.spss("rt_example.sav", to.data.frame = T, reencode = "utf8")
summary(data_rt)
Дадут результат
gender rt1 rt2
муж:30 Min. :194.0 Min. :195.0
жен:19 1st Qu.:241.0 1st Qu.:245.0
NA's: 1 Median :256.0 Median :261.0
Mean :254.7 Mean :262.2
3rd Qu.:263.0 3rd Qu.:280.2
Max. :315.0 Max. :305.0
NA's :1 NA's :2
Информация о пропущенных значениях (NA) содержится в последней строчке каждого столбца. Таким образом, можно увидеть, что информация о поле пропущена у одного испытуемого, фоновое время не введено у одного человека, а второй замер не сделан у двоих испытуемых. При наличии пропущенных значений основные функции, такие как mean или sd по умолчанию дают результат NA. Однако, если указать дополнительный аргумент na.rm = TRUE, то будут рассчитана соответствующая статистика с исключением пропущенных значений:
> mean(data_rt$rt1) [1] NA > mean(data_rt$rt1, na.rm = TRUE) [1] 254.7143
Функции describe и describeBy из пакета psych исключают пропущенный данные по умолчанию:
> require(psych)
Загрузка требуемого пакета: psych
> describe(data_rt)
vars n mean sd median trimmed mad min max range skew kurtosis se
gender* 1 49 1.39 0.49 1 1.37 0.00 1 2 1 0.45 -1.84 0.07
rt1 2 49 254.71 27.45 256 254.61 22.24 194 315 121 0.09 0.02 3.92
rt2 3 48 262.17 25.25 261 263.10 28.17 195 305 110 -0.33 -0.27 3.65
При желании можно исключить строки с пропущенными данными с помощью функции na.omit:
> data_rt_full <- na.omit(data_rt)
> summary(data_rt_full)
gender rt1 rt2
муж:28 Min. :194.0 Min. :195.0
жен:18 1st Qu.:238.8 1st Qu.:246.5
Median :256.0 Median :263.5
Mean :253.5 Mean :263.5
3rd Qu.:261.8 3rd Qu.:280.8
Max. :315.0 Max. :305.0
Пока мы ограничимся этими общими замечаниями, но ещё будем возвращаться к теме обработки пропущенных значений в нашем учебнике.
Упражнение П1.3(14). В качестве итогового упражнения мы предлагаем читателю самостоятельно выполнить следующее задание. В файле WritingSkills.sav приведены результаты исследования письма у детей, учащихся первого и второго классов. В качестве экспериментального задания им давали списать небольшой текст. В качестве показателей уровня развития навыка письма регистрировались два параметра — время выполнения заданий в секундах и количество допущенных при письме ошибок. Файл данных, таким образом, содержит три показателя: класс, в котором обучался испытуемый (переменная group), время выполнения задания (переменная time) и количество допущенных ошибок (переменная mistakes).
- Считайте эти данные в таблицу данных (название выберите по своему усмотрению)
- Вычислите средние показатели времени списывания и количества ошибок в первом и во втором классе.
- Нарисуйте графики изменения этих двух показателей.
В заключение нашего краткого введения ещё раз отметим, что освоение R требует отдельных усилий, настойчивой самостоятельной работы, и в рамках такого сжатого описания мы дали, безусловно, не исчерпывающее описание основ этого языка обработки. Одна из целей этого введения – продемонстрировать, что использование этого инструмента далеко не так сложно, как может показаться неподготовленному пользователю. Однако для уверенной и эффективной работы мы настоятельно рекомендуем заинтересованному читателю воспользоваться материалами, указанными в начале этого раздела и развить базовые навыки работы с языком R.
[1] Packages также иногда называют библиотеками, мы будем использовать буквальный перевод.
[2] Заметим, что также широко распространено использование языка Python, но в данном случае мы сосредотачиваемся на R. Ведутся дебаты, какой из языков «лучше» (см., например, https://www.educba.com/r-vs-python/, https://blog.udemy.com/r-vs-python-which-is-best/), каждый из них имеет свои сильные и слабые стороны. Также довольно широко распространён язык m, который до недавнего времени мог быть использован только в коммерческой программе Matlab, но в последние годы создана бесплатный аналог этой программы Octave, практически не уступающая по своему функционалу коммерческой версии.
[3] При первом запуске Rstudio или нового проекта область скриптов (1) по умолчанию отсутствует, но появляется при создании нового файла (в меню file — new file — R script или сочетание клавиш ctrl-shift-N).
[4] Обращаем внимание пользователей системы Windows, что в R разделители папок – это прямой слэш (/) в отличие от стандартного для Windows обратного слэша (\). То есть, например, полный путь к файлу example.csv, который расположен в папке learn R, которая находится в папке Dropbox на диске С в R описывается так: C:/Dropbox/learn R/example.csv.
[5] Здесь и далее переменная – это объект языка, содержащий какую-либо информацию – число, символ, ил набор объектов.
[6] Заметим, что аналогичный результат может быть получен командой b <- matrix(c(1:8), 2, 4).
[7] Двойной знак равенства (==) используется для проверки логических условий.
[8] Выражение a:b в R является эквивалентом перечисления цифр от a до b.
[9] О типах шкал см. подробнее параграф 1.1 нашего учебника.
[10] У функции read.csv есть много дополнительных аргументов, указывающих на используемый разделитель (иногда это могут быть и не запятые), тип разделителя десятичных дробей (в русской локализации это запятые, а в английской – точки), наличие названия переменных в первой строке и т. п. Подробное описание возможностей этой (равно как и любой другой) функции можно с помощью команды help(«read.csv»).
[11] В зависимости от настроек системы установка пакетов может требовать прав администратора, поэтому при возникновении проблем можно попытаться запустить Rstudio от имени администратора системы.
[12] Более подробное описание этого исследования и его результатов можно найти, например, в статье: Корнеев А.А., Протасова Е.Ю. Письмо у финско-русских билингвов младшего школьного возраста // Психолингвистические аспекты изучения речевой деятельности. — Т. 13 из Труды Уральского психолингвистического общества. — Уральский государственный педагогический университет Екатеринбург, 2015. — С. 107–122.
[13] Термин «Описательная статистика» в данном случае обозначает, что будут рассчитываться параметры, описывающие распределение данных (в первую очередь, по умолчанию — среднее значение и стандартное отклонение, подробнее см. параграф 3.1).
[14] Знак # в R означает начало комментария, все следующее за ним до конца строки не выполняется интерпретатором и в комментарии можно писать любой поясняющий текст.
[15] Если читателю кажется это описание слишком громоздким, можно для начала просто иметь в виду, что выборочные значения, «выпадающие» за пределы усов могут рассматриваться как аномальные значения или «выбросы» (outliers). Что делать с такими значениями с точки зрения статистической обработки – отдельный вопрос и требует отдельного обсуждения, в нашем учебнике мы будем возвращаться к этому вопросу.
[16] Отметим, что умение пользоваться справкой (вызываемой командой help), а также использование поиска для ответа на возникающие вопросы является важным навыком при обучении и использовании R. С помощью поисковых систем можно найти ответы на очень многие вопросы, которые могут сильно облегчить обучение и работу.