Чтобы читатель, незнакомый со статистическим пакетом Jamovi, мог выполнять предлагаемые нами упражнения и задания, остановимся на базовых элементах этой программы. Отметим, что в версиях программы, начиная с версии 2.3.3 появился перевод интерфейса на русский язык, однако он пока имеет недостатки с точки зрения точности терминологии и мы описываем работу с интерфейсом на английском языке. По умолчанию Jamovi при установке устанавливает язык системы в соответствии с настройками операционной системы, при желании его можно переключить в настройках программы (они вызываются нажатием трех точек в правом верхнем углу окна программы).
Главное рабочее окно программы организовано в виде таблицы данных (рис. П1.2(1)).

Рис. П1.2(1). Окно данных в Jamovi
В левом верхнем углу расположено основное меню, первый пункт (три полоски ![]() ) открывает окно работы с файлами — можно открыть файлы данных в различных форматах, сохранять данные и результаты расчетов и импортировать их в различные форматы. Файлы jamovi имеют расширение omv и позволяют хранить как данные, так и результаты расчетов и анализа в одном файле. Также в jamovi можно загружать данные в самых разных форматах — csv, xls(x), данные в формате других статистических пакетов — sav (SPSS), dta (Stata), xpt (SAS), Rdata (R) и др. Вторая вкладка — Variables — предназначена для редактирования имен и свойств переменных, следующая — Data — открывает окно данных и меню работы с ними, четвертая вкладка — Analyses — открывает меню анализа данных, наконец, последняя — Edit — позволяет редактировать получаемые результаты — вставлять в них комментарии, меня заголовки и т.п. Остановимся подробнее на устройстве таблицы данных.
) открывает окно работы с файлами — можно открыть файлы данных в различных форматах, сохранять данные и результаты расчетов и импортировать их в различные форматы. Файлы jamovi имеют расширение omv и позволяют хранить как данные, так и результаты расчетов и анализа в одном файле. Также в jamovi можно загружать данные в самых разных форматах — csv, xls(x), данные в формате других статистических пакетов — sav (SPSS), dta (Stata), xpt (SAS), Rdata (R) и др. Вторая вкладка — Variables — предназначена для редактирования имен и свойств переменных, следующая — Data — открывает окно данных и меню работы с ними, четвертая вкладка — Analyses — открывает меню анализа данных, наконец, последняя — Edit — позволяет редактировать получаемые результаты — вставлять в них комментарии, меня заголовки и т.п. Остановимся подробнее на устройстве таблицы данных.
Столбцы в этой таблице — это измеряемые параметры (переменные), а строки — это наблюдения. Если рассматривать результаты психологических исследований, каждая строка, как правило, включает набор данных об одном испытуемом, либо об отдельных пробах, которые выполняет испытуемый. Измеряемые параметры могут быть любого типа, например, имя испытуемого, его возраст, пол, результаты различных опросников, заполненных испытуемым, время реакции в каком-либо эксперименте и т.п. В зависимости от информации, содержащейся в переменных, они могут быть трех типов: целые числа (integer), дробные (decimal) или текстовые (text). Для управления переменными, изменения их имен, типов и т.п. в Jamovi нужно перейти на вкладку Data. Рассмотрим модельный пример ввода данных исследования в Jamovi.
Пример П1.2(2) Организация ввода данных исследования в Jamovi
Проведено тестирование уровня ситуативной и личностной тревожности 10 студентов (5 мужчин и 5 женщин). В результате тестирования у каждого испытуемого был рассчитан итоговый балл ситуативной и личностной тревожности. Чем выше балл, тем более выражен тот или иной вид тревожности, максимально возможный балл равнялся 30. Также исследователи регистрировали пол и возраст испытуемых. Помимо этого, студентам задавался следующий вопрос: «Насколько часто Вы волнуетесь перед экзаменами?». Испытуемые должны были обвести один из вариантов ответа: «Почти никогда», «Редко», «Иногда», «Часто/почти всегда».
Полученные в ходе исследования результаты представлены в таблице П1.2(3).
Таблица П1.2(3). Данные исследования личностной и ситуативной тревожности.
| № | Имя | Пол | Возраст | Ответ на вопрос «Как часто я волнуюсь перед экзаменом?» | Ситуативная тревожность | Личностная тревожность |
| 1 | Н.И. | Женский | 20 | Часто/почти всегда | 20 | 26 |
| 2 | К.Л. | Мужской | 18 | Почти никогда | 18 | 16 |
| 3 | П.Д. | Мужской | 18 | Иногда | 15 | 20 |
| 4 | У.Р. | Женский | 18 | Часто/почти всегда | 17 | 21 |
| 5 | И.К. | Мужской | 19 | Редко | 19 | 17 |
| 6 | Т.К. | Женский | 20 | Редко | 17 | 18 |
| 7 | А.Н. | Женский | 21 | Иногда | 21 | 19 |
| 8 | Г.М. | Мужской | 21 | Почти никогда | 10 | 19 |
| 9 | В.Н. | Женский | 19 | Иногда | 19 | 18 |
| 10 | Л.Н. | Мужской | 20 | Иногда | 20 | 20 |
Рассмотрим, как корректно ввести полученные результаты в Jamovi. При открытии программы появляется пустая таблица данных. Для начала необходимо разобраться, какие переменные включены в исследование и как их оптимально закодировать для ввода в Jamovi. Выделим переменные в нашем исследовании: две переменные, измеренные в номинативной шкале: имя испытуемых и пол; ответ на вопрос анкеты (шкала порядка) и три интервальные шкалы: возраст, ситуативная тревожность, личностная тревожность. Кроме того, есть служебный столбец с числовым кодом испытуемых, его стоит сохранить на случай, если понадобится восстановить исходный порядок строк. Следовательно, в нашей таблице будет 7 столбцов.
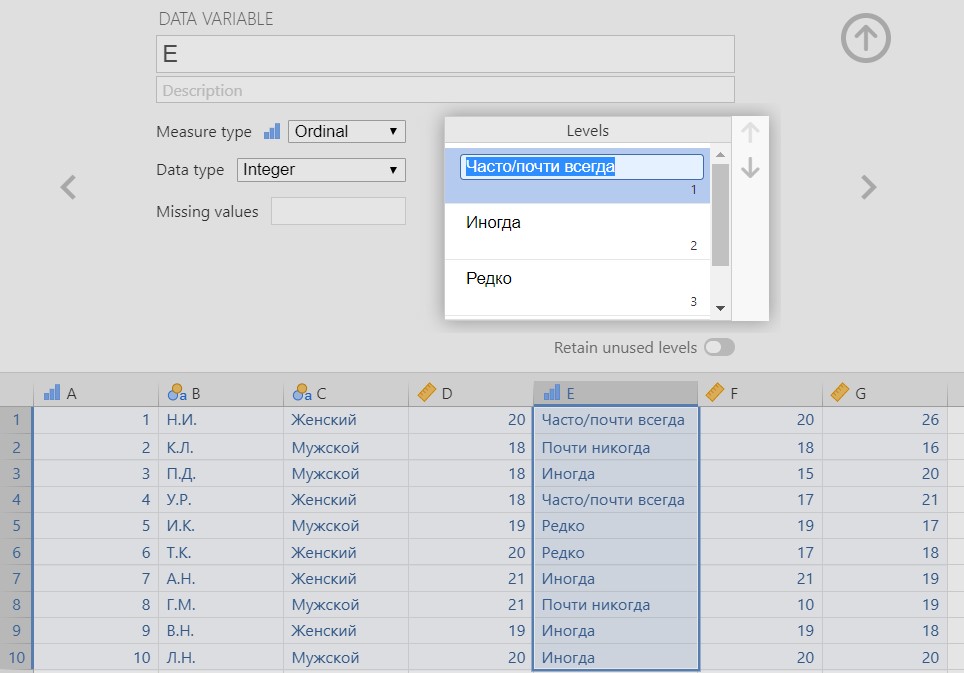 Рис. П1.2(4). Заполненное окно описания данных
Рис. П1.2(4). Заполненное окно описания данных
Вставим в файл все значения из таблицы, кроме первой строки с названиями переменных. По умолчанию все переменные именуются в алфавитном порядке. Посмотрим на описание первого столбца, переменной А. Выбор типа переменной и другие настройки вида переменных производим в меню, которое вызывается двойным щелчком по заголовку переменной, либо через вкладку Data — Setup:

Рис. П1.2(5). Меню редактирования параметров переменных, слева — выбор типа шкалы, справа – выбор типа данных.
А – название столбца переменной. Поскольку это числовой код испытуемого, обозначим его как N. Названия столбцам стоит давать латинскими буквами и максимально короткие, но осмысленные, чтобы легко было найти нужную переменную в списке. В отличие от SPSS пробелы в названии допускаются, но для совместимости лучше вместо пробелов использовать нижние подчеркивания.
Description – описание содержания переменной. Здесь можно дать полное название переменной, в том числе на русском языке, но опыт показывает, что кириллическая кодировка может «слететь», поэтому рекомендуем использовать латиницу.
Measure type – тип шкалы: Nominal — номинативная, Ordinal — порядковая, Continuous — метрическая, ID – номер наблюдения. Выбираем последний вариант, так как он в точности соответствует содержанию первой переменной из нашего примера, см. рис. П1.2(5) слева. Заметим, что инициалы испытуемого (переменная В) тоже представляют собой его ID, но у нескольких испытуемых инициалы могут совпасть, поэтому оставим переменную номинативной.
Data type – уточняет тип вводимых данных: Integer – целые числа, например, ранги, Decimal – любые числа, в том числе с дробной частью, Text – текст или любое содержание, не являющееся числом (рис. П1.2(5)).
Missing value – здесь можно указать, как кодируются пропущенные значения в случае, когда это не пустые ячейки (например, при разметке особыми числами или принятым в программировании термином “NA” – not available). В рамках данного курса этот параметр можно оставить без изменений, т.к. все пропущенные значения будут размечаться пустыми ячейками.
Для всех переменных, кроме Е («Ответ на вопрос «Как часто волнуюсь перед экзаменом?»»), достаточно выбрать подходящее название, описание и значения Measure type и Data type. Ответ на вопрос анкеты нужно закодировать так, чтобы текстовые значения переменной воспринимались программой как порядковые. Для этого введем следующую кодировку: 1 – «Часто/почти всегда», 2 – «Иногда», 3 – «Редко», 4 – «Почти никогда». Заменим все текстовые значения числовыми (на больших массивах данных кодировку стоит продумывать заранее и вносить в Jamovi подготовленные данные). Теперь в поле Levels указываем значения каждого уровня переменной (см. рисунок П1.2(4)).
Откройте файл с готовой разметкой appendix1.omv и назовите переменные F и G по смыслу, убедитесь, что у всех переменных есть понятные описания. Перекодируйте переменную sex – это стоит сделать хотя бы потому, что обозначения уровней переменных иногда приходится менять и проще изменить обозначения для переменной, закодированной числами (работа только с описанием переменной), чем менять содержание таблицы данных. Теперь файл подготовлен к анализу данных – можно проводить различные расчеты, строить диаграммы и т.п., остальные переменные не требуют перекодировки.
Пример П1.2(6) Некоторые возможности вкладки Data в Jamovi
Меню Variables имеет дело с переменными. Возможности меню Setup рассмотрены в предыдущем разделе, остановимся на нескольких других.
Compute – создает новую переменную и вставляет ее справа от выделенного столбца, дальше с помощью небольшого набора встроенных функций (см. список Functions) можно создать/вычислить новую числовую или логическую переменную, или преобразовать имеющиеся переменные (см. список Variables). Например:
ABS(Х) возвращает абсолютное значение, то есть вычисляет модуль содержимого количественной переменной Х.
SQRT(X) возвращает квадратный корень из Х.
Z(X, group_by = Y) возвращает нормированное значение переменной X, можно вывести независимо нормированные значения для групп данных, заданных переменной Y.
Все функции снабжены кратким описанием. На рисунке П1.2(7) показана запись для вычисления разности значений переменных F и G.
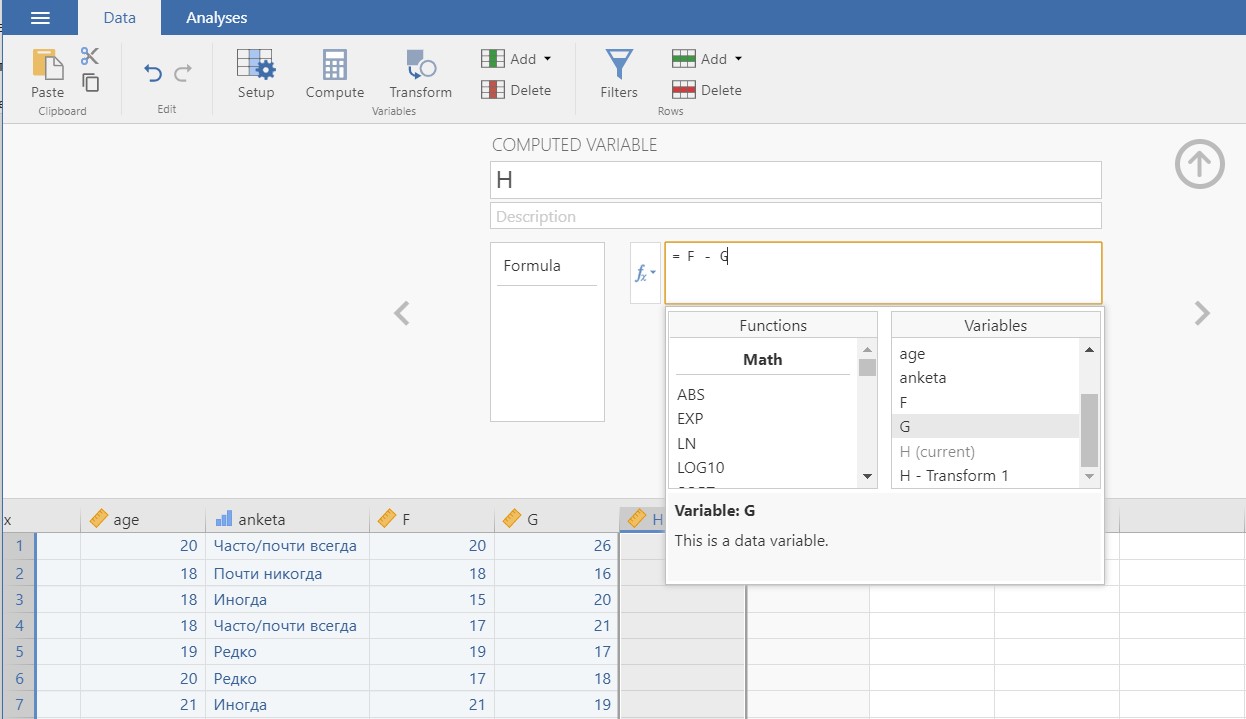 Рис. П1.2(7). Меню Compute – создание переменных
Рис. П1.2(7). Меню Compute – создание переменных
Transform – создает новую переменную справа от выделенной, позволяет преобразовывать существующие переменные с использованием небольшого набора встроенных функций и задавать логические условия для применения преобразований (подробнее см. в руководстве пользователя).
Add – позволяет вставить новую переменную справа от выделенной, либо в конце всего набора переменных. Это может быть просто пустая переменная, либо переменная типа Computed или Transformed, которые были описаны выше.
Delete – удаление переменной.
Меню Rows имеет дело со строками данных, позволяет добавлять новые строки – Add, удалять выделенные – Delete и фильтровать их – Filter. Фильтрация, или отбор наблюдений для анализа, нужна очень часто, рассмотрим эту функцию подробнее.
На рисунке П1.2(8) показаны два фильтра: Filter 1 и Filter 2. Filter 1 состоит из двух условий – первое отбирает строки, в которых переменная sex принимает значение «Мужской» («==» означает эквивалентность, «равно», а кавычки вокруг значения переменной необходимы, так как переменная sex является номинативной), второе условие отбирает строки, в которых переменная age принимает любые значения, кроме 19 («!=» означает отрицание равенства, «не равно», кавычки для значения переменной не требуются, так как она числовая). Можно задавать и другие условия, например, «>» и «<» отбирают строки, в которых выбранная переменная принимает значения строго больше или строго меньше указанного, а «>=» делает это условие нестрогим («больше или равно»). Условия связаны логическим оператором and, который требует одновременного выполнения обоих условий, принимается так же логическое ИЛИ (or – требует выполнения любого из условий). В таблице с данными фильтр представлен столбцами Filter 1 и F1 (2), каждый из которых отображает результат отбора по одному из условий. Серым выделены строки с данными, которые не удовлетворяют любому из условий – отобранными оказались строки с данными мужчин любого возраста, кроме 19 лет (строка 5). Добавление условий в фильтр производится с помощью знака ![]() в строке с первым условием. Новый фильтр можно добавить с помощью знака
в строке с первым условием. Новый фильтр можно добавить с помощью знака ![]() слева от окна с фильтрами – как видим, второй фильтр пока никак не задан, но соответствующая ему переменная Filter 2 содержит отметки наблюдений, отобранных по первому фильтру. Любой фильтр можно активировать или деактивировать переключением значка
слева от окна с фильтрами – как видим, второй фильтр пока никак не задан, но соответствующая ему переменная Filter 2 содержит отметки наблюдений, отобранных по первому фильтру. Любой фильтр можно активировать или деактивировать переключением значка ![]() .
.

Рис. П1.2(8). Меню Filter для отбора наблюдений (строк)
Упражнение П1.2(9). В таблице П1.2(10) представлены показатели эмоционального интеллекта в трех группах испытуемых (будем считать, что это интервальная шкала). Введите результаты эксперимента в Jamovi, не забыв создать переменную для кодировки групп.
Таблица П1.2(10). Данные исследования эмоционального интеллекта у испытуемых с истерическим расстройством
| Номер испытуемого | Балл по шкале «Эмоциональная осведомленность» | Балл по шкале «Распознавание эмоций других людей» |
| Здоровые испытуемые | ||
| 1 | 4 | 6 |
| 2 | 6 | 5 |
| 3 | 6 | 3 |
| 4 | 3 | 2 |
| 5 | 4 | 2 |
| Испытуемые с истерическим расстройством | ||
| 6 | 6 | 5 |
| 7 | 7 | 4 |
| 8 | 3 | 5 |
| 9 | 4 | 6 |
| 10 | 3 | 5 |
| Испытуемые с шизодидным расстройством | ||
| 11 | 3 | 4 |
| 12 | 5 | 2 |
| 13 | 2 | 5 |
| 14 | 6 | 3 |
| 15 | 2 | 4 |
Для тренировки задайте фильтр, который отбирал бы женщин старше 19 лет, и второй фильтр, отбирающий 18-летних испытуемых, которые дают в анкете любые ответы, кроме «Почти никогда».
Пример П1.2(11). Первичный статистический анализ в Jamovi
Перейдем к описанию данных – графическому и числовому. Прежде всего заметим, что результаты вычислений можно сохранить и потом при необходимости отредактировать только при сохранении данных в собственном формате Jamovi *.omv.
В файле WritingSkills.sav приведены результаты исследования письма у детей, учащихся первого и второго классов. В качестве экспериментального задания им давали списать небольшой текст. В качестве показателей уровня развития навыка письма регистрировались два показателя — время выполнения заданий в секундах и количество допущенных при письме ошибок. Файл данных, таким образом, содержит три показателя: класс, в котором обучался испытуемый (переменная group), время выполнения задания (переменная time) и количество допущенных ошибок (переменная mistakes).
Первая задача, которую можно решить с помощью Jamovi — это расчет описательной статистики [4] времени, затрачиваемого на письмо одной буквы на двух языках. Для этого необходимо на вкладке Analyses выбрать меню Exploration — Descriptives.
После этого на экране появится диалоговое окно расчета описательной статистики. Исходный вид окна изображен на рис. П1.2(12), три переменные перенесены из левого окна в правые: time и mistakes в окне Variables, именно для них мы будем считать описательные статистики, а переменная class находится в окне Split by – это очень удобный способ разбить все значения на группы по выбранной переменной и анализировать их по отдельности – в данном случае можно рассмотреть детей с разной доминантностью по языку отдельно друг от друга.
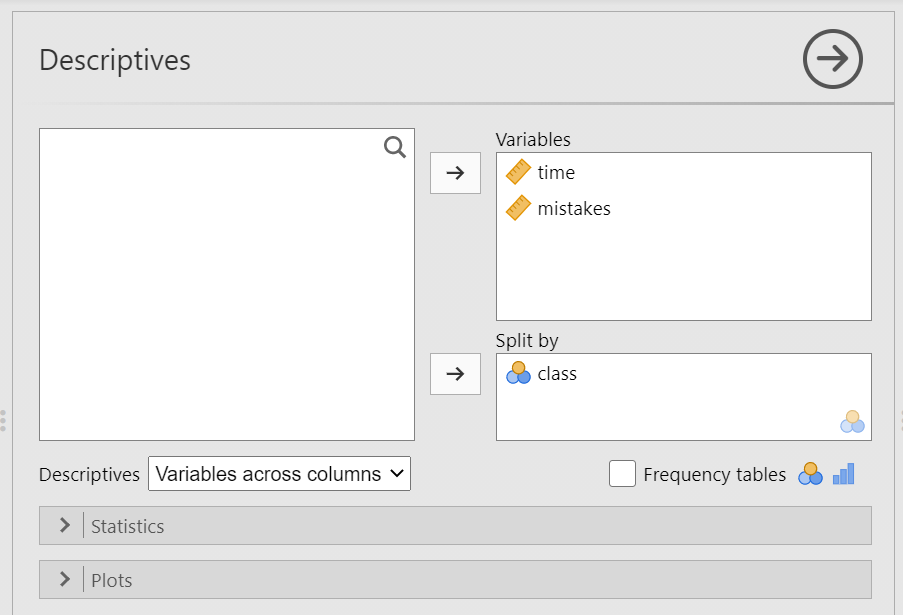
Рис. П1.2(12). Окно выбора переменных и установки параметров расчета описательной статистики
Под окнами с переменными находятся два раскрывающихся меню – Statistics для выбора необходимых описательных статистик и Plots для выбора подходящих графиков (рис. П1.1(13)).

Рис. П1.2(13). Диалоговое окно для выбора нужных описательных статистик и графиков
Значения, которые программа выводит по умолчанию, отмечены галочками. Рассмотрим полный набор возможностей меню Statistics:
Sample Size – позволяет вывести количество валидных наблюдений (N) и количество пропущенных наблюдений (Missing). Наши данные полные, поэтому галочку с Missing стоит снять.
Percentile Values – выводит значения квартилей (Quartiles) и процентилей (Cut points for) при разделении выборки на произвольное число групп (до 10).
Central Tendency – выводит значения различных мер центральной тенденции, включая среднее арифметическое (Mean), медиану (Median), моду (Mode) и дополнительно сумму всех значений переменной (Sum).
Dispersion – выводит показатели вариативности выборочных значений, а именно, значение стандартного отклонения (Std. deviation), дисперсии (Variance), разброса (Range), максимума (Maximum), минимума (Minimum) и стандартной ошибки оценки среднего (S.E. Mean).
Distribution – выводит показатели асимметрии (Skewness) и эксцесса (Kurtosis) вместе с показателями их стандартных ошибок.
Normality – выводит результаты теста Шапиро-Уилка для проверки нормальности выборочного распределения (Shapiro—Wilk).
Переходим к меню Plots, в котором упомянем только несколько вариантов:
Histogram – гистограмма – хороший вариант для количественных переменных с большим диапазоном значений или для любых метрических шкал.
Box plot и Data – ящичная диаграмма (или «ящик с усами») и одномерная диаграмма рассеяния часто используются для отображения количественных данных при сравнении групп. Ящики удобны для обнаружения выбросов в выборке, а диаграмма рассеяния более полно отображает особенности распределения данных (два формата графика задаются через раскрывающееся меню).
Bar plot – столбиковая диаграмма – аналог гистограммы для номинативных переменных.
Такие меню настройки дополнительных параметров есть практически в каждой разновидности статистического анализа, представленного в Jamovi. За подробной и исчерпывающей информацией читатель может обратиться к руководству по Jamovi. В рамках этой книги при описании различных расчетов, проводимых в Jamovi, мы будем указывать на параметры, имеющие наибольшую важность при базовом освоении темы.
Результаты всех расчетов и все графики выводятся в правой части экрана и обновляются при любом изменении настроек меню или содержания таблицы с данными. С одной стороны, это очень удобно и наглядно – можно экспериментировать с данными и смотреть, как меняются значения статистик. С другой стороны, иногда важно сохранить результаты нескольких вариантов анализа. Возможность скопировать результаты анализа (Copy), дублировать их в выводе Jamovi (Duplicate), экспортировать в pdf или другой формат (Export…), или вовсе удалить (Remove) есть – для этого достаточно щелкнуть правой кнопкой мыши по заголовку или любому элементу результатов, см. рис. П1.2(14).
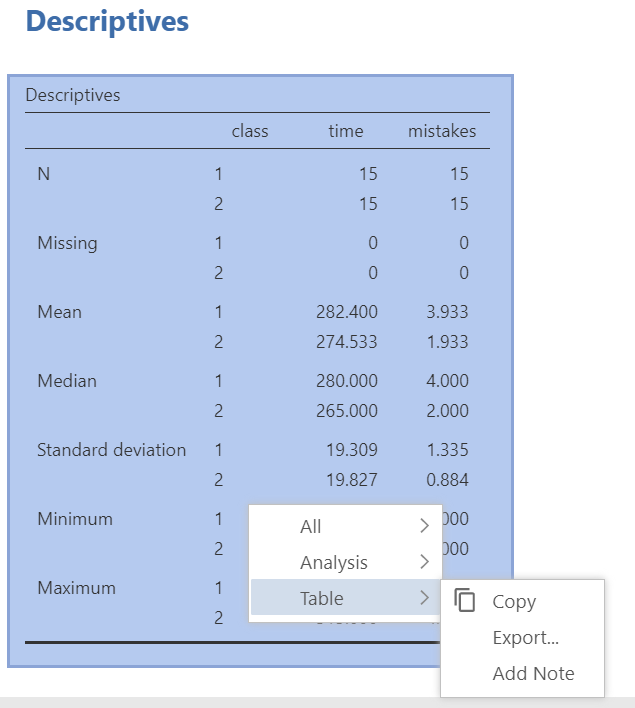 Рис. П1.2(14). Описательные статистики
Рис. П1.2(14). Описательные статистики
По таблице с описательными статистиками можно увидеть, что первоклассники в среднем тратят на выполнение задания больше времени и совершают больше ошибок, при этом стандартное отклонение по времени больше среди второклассников, а первоклассники, наоборот, больше различаются по количеству допущенных ошибок (формально, если количество ошибок рассматривается как порядковая шкала, особенности распределения для нее нужно смотреть по показателям медианы и полумежквартильного размаха). Задача оценки относительной величины и значимости наблюдаемых различий в исследованиях такого типа описана в главах 5 и 6.
Теперь посмотрим на графическое представление данных. Начнем с Bar Plot – на рис. П1.2(15) в левом столбце представлены столбчатые диаграммы для переменных time, mistakes и class, а в правом столбце такие же диаграммы, но с группировкой по переменной class. Итак, для метрической шкалы time вертикальная ось отображает время выполнения задания, высота столбика определяется выборочным средним, усы показывают вариативность – заметно, что второклассники не намного быстрее первоклассников. Для порядковой шкалы mistakes и номинативной шкалы class значения переменных отложены по горизонтали, а высота столбиков отображает частоту встречаемости каждого из значений в выборке. По правому графику видно, откуда берется разница в дисперсиях – во втором классе не только уже диапазон значений, но некоторые из них встречаются заметно чаще других (1 и 2 ошибки). Для тренировки имеет смысл сравнить в двух классах значения таких описательных статистик как асимметрия и эксцесс.
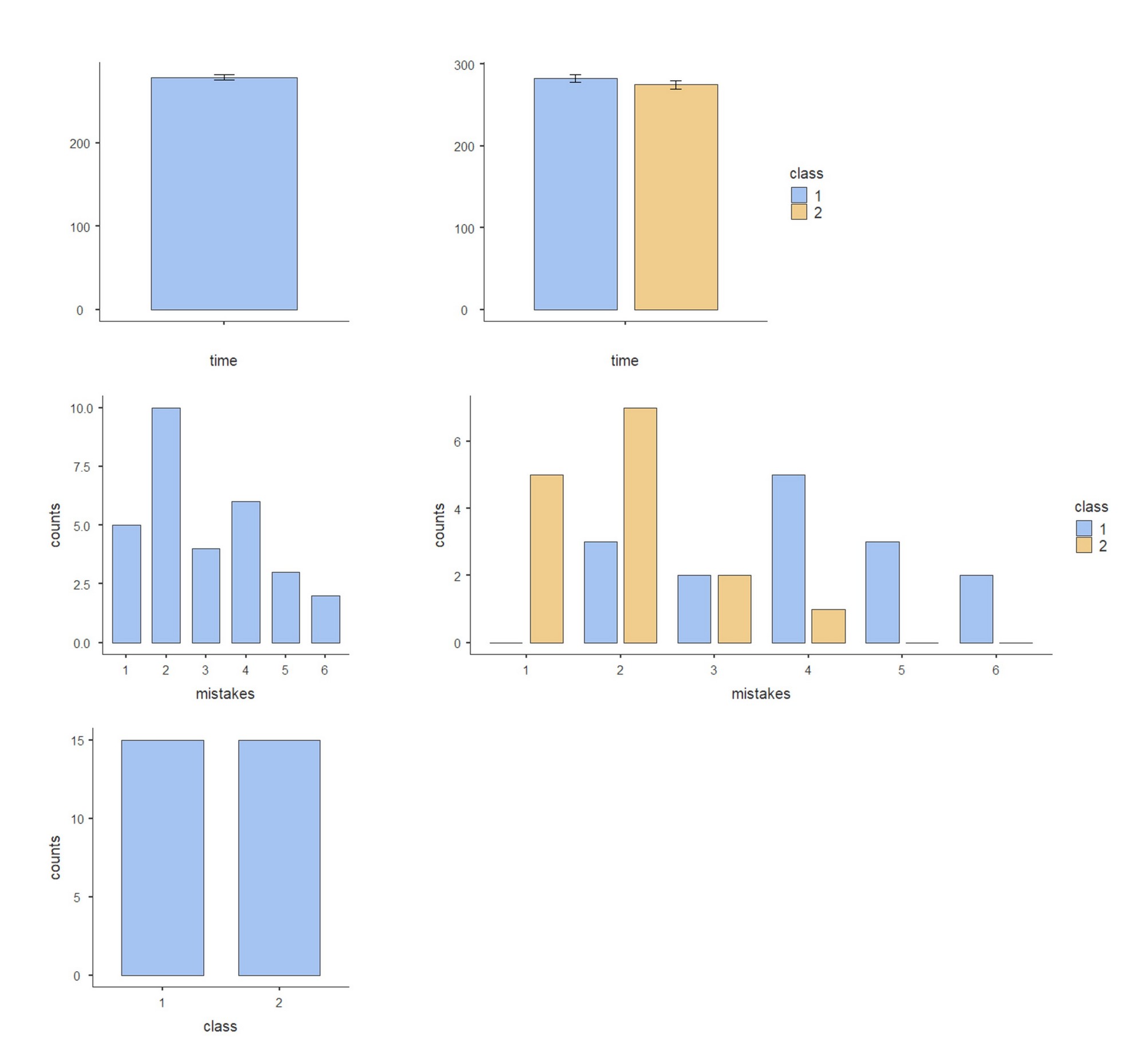
Рис. П1.2(15). Столбиковые диаграммы
Гистограммы для переменных time и mistakes похожи, в отличие от столбиковых диаграмм для этих переменных. На горизонтальной оси откладываются значения переменной, а вертикальная ось отображает плотность распределения (density), при большой вариативности значений соседние значения объединяются в один столбик гистограммы, см. рис. П1.2(16). Можно заметить, что гистограммы для разных классов расположены одна под другой – это удобно при сравнении распределений «на глаз».
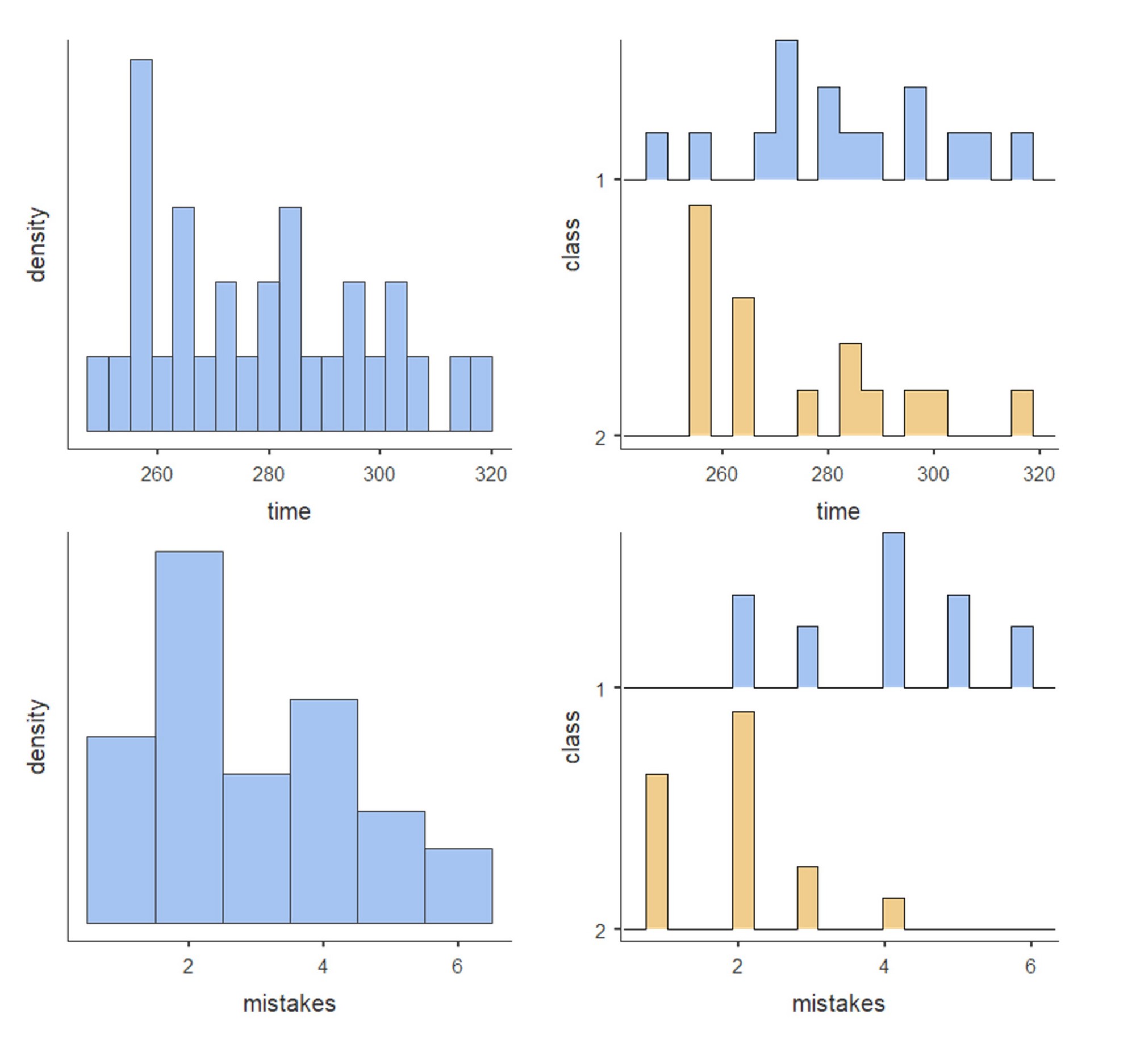
Рис. П1.2(16). Гистограммы
Модуль scatr дает также возможность нарисовать диаграмму рассеивания, недоступную через меню Descriptives. Выбираем функцию Scatterplot, расположенную в меню Data и расставляем переменные time и mistakes по осям, а переменную class указываем как группирующую, результат представлен на рис. П1.2(17):
 Рис. П1.2(17). Диаграмма рассеивания
Рис. П1.2(17). Диаграмма рассеивания
Поэкспериментировать с настройками и сравнить две группы школьников по показателю скорости письма можно на основе готового файла writingSkills.omv. Для начала можно вычислить на основе переменной time скорость выполнения задания в минутах, в данном исследовании это более понятная величина.
Упражнение П1.2(18).
В качестве материала возьмем данные исследования скорости письма у детей-билингвов младшего школьного возраста. Мы предлагали второклассникам, учащимся в Финско-русской школе города Хельсинки, переписать два небольших текста — один на русском, второй на финском языках [3]. Процесс письма регистрировался с помощью графического планшета и затем подвергался обработке и анализу. В частности, оценивалась скорость письма на двух языках, основным показателем было среднее время, затрачиваемое ребенком на написание одной буквы текста. Результаты этого исследования содержатся в файле WritingBilingual.sav. Каждый испытуемый в этом наборе данных характеризуется четырьмя параметрами: идентификационным номером (переменная id), доминантностью русского или финского языка (в зависимости от основного «домашнего» языка, используемого в семье, переменная group), средним временем написания буквы на русском и на финском языках (переменные WritingLetRus и WritingLetFin соответственно).
- Вычислите средние показатели скорости письма второклассников с разными доминантными языками.
- Нарисуйте графики для шкал по отдельности и для переменных WritingLetRusи WritingLetFin вместе, соотнесите их с данными описательных статистик.
Дополнительные модули анализа данных в Jamovi.
В Jamovi есть возможность расширить базовый функционал программы, установив дополнительные модули. Для этого нужно нажать на кнопку Modules в правом верхнем углу рабочего окна и зайти в пункт jamovi library (см. рис. П1.2(19)).
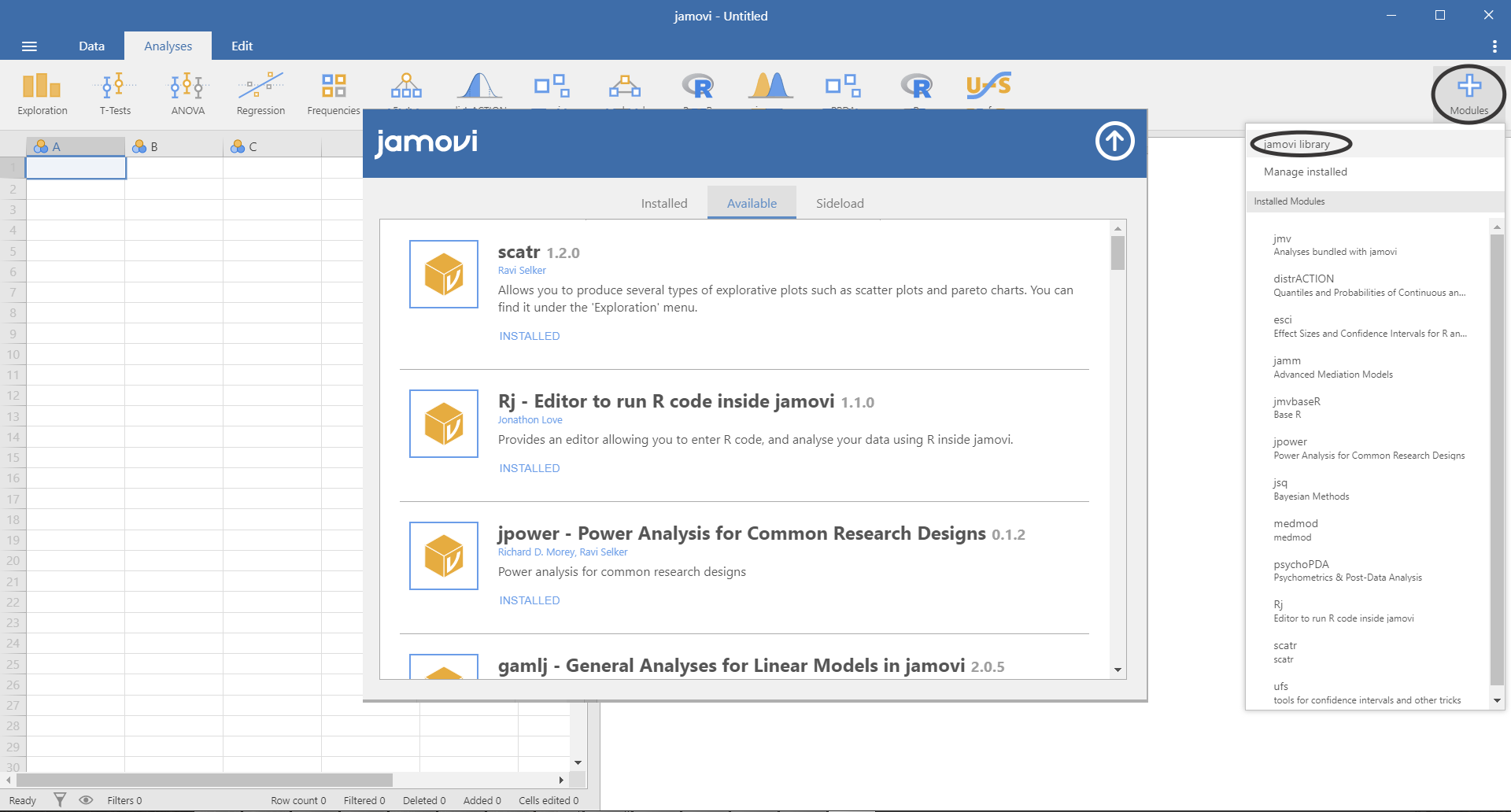 Рис. П1.2(19). Окно установки дополнительных моделей Jamovi.
Рис. П1.2(19). Окно установки дополнительных моделей Jamovi.
В рамках нашего учебника мы не будем останавливаться подробно на всех дополнительных модулях, но укажем те, которые могут быть полезны при использовании обсуждаемых методов.
- distrAction — модуль содержащий калькулятор квантилей и вероятностей для разных типов распределений.
- medmod — модуль, предназначенный для проведения анализа медиации и модерации.