Как мы уже писали, в задачи нашего учебника не входит подробное обсуждение работы в SPSS, однако, чтобы читатель, незнакомый с этим статистическим пакетом, мог выполнять предлагаемые нами упражнения и задания, остановимся на базовых элементах этой программы.
Главное рабочее окно программы организовано в виде матрицы данных (рис. П1(1)).
Рис. П1.1(1). Окно данных в SPSS
Столбцы в этой таблице — это измеряемые параметры (переменные), а строки — это наблюдения. Если рассматривать результаты психологических исследований, каждая строка, как правило, включает набор данных об одном испытуемом. В некоторых случаях, например в психосемантических исследованиях, строки могут содержать другую информацию, однако мы не будем подробно останавливаться на этом. Измеряемые параметры могут быть любого типа, например, имя испытуемого, его возраст, пол, результаты различных опросников, заполненных испытуемым, время реакции в каком-либо эксперименте и т.п. В зависимости от информации, содержащейся в переменных, они могут быть разных типов. Два основных типа, которые используются чаще всего, — это числовые и символьные переменные. Для управления переменными, изменения их имен, типов и т.п. в SPSS существует режим Представление Переменные (Variable view) [1]. Рассмотрим модельный пример ввода данных исследования в SPSS.
Пример П1.1(2) Организация ввода данных исследования в SPSS
Проведено тестирование уровня ситуативной и личностной тревожности 10 студентов (5 мужчин и 5 женщин). В результате тестирования у каждого испытуемого был рассчитан итоговый балл ситуативной и личностной тревожности. Чем выше балл, тем более выражен тот или иной вид тревожности, максимально возможный балл равнялся 30. Также исследователи регистрировали пол и возраст испытуемых. Помимо этого, студентам задавался следующий вопрос: «Насколько часто Вы волнуетесь перед экзаменами?». Испытуемые должны были обвести один из вариантов ответа: «Почти никогда», «Редко», «Иногда», «Часто/почти всегда».
Полученные в ходе исследования результаты представлены в таблице П1(3).
Таблица П1.1(3). Данные исследования личностной и ситуативной тревожности.
| № | Имя | Пол | Возраст | Ответ на вопрос “Как часто я волнуюсь перед экзаменом?” | Ситуативная тревожность | Личностная тревожность |
| 1 | Н.И. | Женский | 20 | Часто/почти всегда | 20 | 26 |
| 2 | К.Л. | Мужской | 18 | Почти никогда | 18 | 16 |
| 3 | П.Д. | Мужской | 18 | Иногда | 15 | 20 |
| 4 | У.Р. | Женский | 18 | Часто/почти всегда | 17 | 21 |
| 5 | И.К. | Мужской | 19 | Редко | 19 | 17 |
| 6 | Т.К. | Женский | 20 | Редко | 17 | 18 |
| 7 | А.Н. | Женский | 21 | Иногда | 21 | 19 |
| 8 | Г.М. | Мужской | 21 | Почти никогда | 10 | 19 |
| 9 | В.Н. | Женский | 19 | Иногда | 19 | 18 |
| 10 | Л.Н. | Мужской | 20 | Иногда | 20 | 20 |
Рассмотрим, как корректно ввести полученные результаты в SPSS. При открытии программы появляется пустая таблица данных. Перед вводом данных необходимо разобрать, какие переменные включены в исследование и как их оптимально закодировать для ввода в SPSS. Выделим переменные в нашем исследовании: две переменные, измеренные в номинативной шкале: имя испытуемых и пол; ответ на вопрос анкеты (шкала порядка) и три интервальные шкалы: возраст, ситуативная тревожность, личностная тревожность. Следовательно, в нашей таблице будет 6 столбцов.
На закладке Представление Переменные (Variable View) можно задать имена переменных в первом столбце, озаглавленном Имя (Name). В названиях переменных можно использовать буквы латиницы или кириллицы [2] и цифры, запрещены пробелы и знаки препинания (допустимо использовать нижние подчеркивания и точки). Еще одно требование к названию переменной в SPSS — первый символ не должен быть цифрой. Сразу после ввода переменной на листе появляются ее данные, настроенные по умолчанию: тип переменной, длина переменной (максимальное количество знаков), метка переменной (этот столбец по умолчанию пуст), значение, пропуски, колонки, выравнивание, шкала. После ввода названия переменной можно определить другие ее свойства. В столбце Тип (Type) можно выбрать тип данных. По умолчанию новая переменная имеет числовой формат (Numeric), однако можно указать и другие: числовой с запятой-разделителем, отделяющий десятые и сотые доли, с точкой-разделителем, научное обозначение, дату, доллары и иную валюту и текстовую строку. В практике психологических исследований, как правило, достаточно первого и последнего варианта: числового и текстового. В нашем случае переменная Имя является текстовой, поэтому для нее тип данных нужно изменить на Текстовая (String).
Следующий показатель — Ширина (Width), количество символов в переменной, ее можно варьировать, если данные (например, текст), не умещаются в ячейке.
Четвертый столбец — Знаков после запятой (Decimals) — количество отображаемых у числовых переменных знаков после запятой (при изменении этого свойства меняется именно отображение числа, округления в расчетах не происходит).
Пятый столбец — Метка (Label) — название переменной в исследовании. Здесь может быть указано любое название или пояснение к переменной без ограничений в символах — в том виде, в каком оно будет представлено в таблицах после обработки данных. Это поле необязательно для заполнения, но мы рекомендуем использовать его для более полного и читаемого обозначения переменных, что упрощает форматирование результатов расчетов и делает более понятной саму таблицу данных. Впишем более подробные названия переменных в столбец (рис. П1(4)).
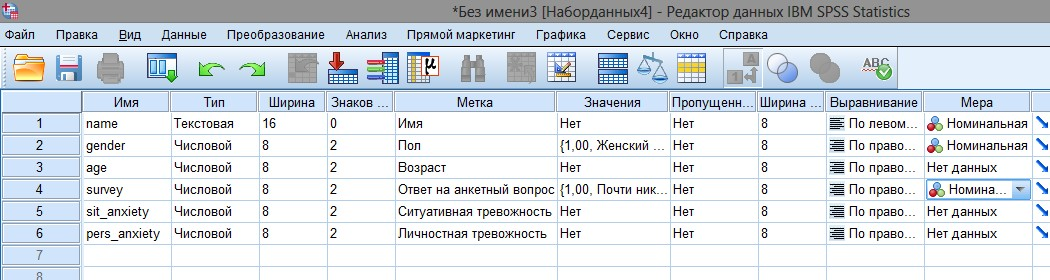
Рис. П1.1(4). Заполненное окно описания данных
В следующем столбце — Значения (Value) — для переменных, измеренных в номинативной шкале, можно указать, какие обозначения для разных уровней переменной были использованы в исследовании. В нашем случае в номинативной шкале выражен показатель Пол (мужской/женский). Показатель Анкета в зависимости от целей и задач исследования можно считать порядковым (мы предполагаем, что ответы «Часто/почти всегда», «Иногда», «Редко», «Почти никогда» выстраиваются в линейную последовательность) и будем кодировать их натуральными числами от 1 до 4.
Чтобы присвоить значения переменной Пол, поставим курсор на вторую строку в столбце Значения и нажмем на многоточие. В появившейся таблице нужно указать числовое значение и его содержание и нажать на кнопку Добавить. Мы будем обозначать женский пол цифрой «1», мужской пол — цифрой «2». Введем эти обозначения в диалоговое окно. Теперь как в таблице данных, так и в таблицах результатов можно будет увидеть словесное обозначение группы испытуемого, а не только ее номер.
На остальных параметрах переменных мы пока останавливаться не будем. Подробную информацию о них можно найти в специальных пособиях по использованию SPSS.
Вернемся к таблице данных, нажав на закладку Представление Данные (Data View) внизу рабочего окна. На листе данных появились названия переменных. Теперь мы можем ввести данные (рис. П1(5)). (После ввода каждого значения в соответствующую клетку можно нажать клавишу Enter или любую стрелку на клавиатуре.)
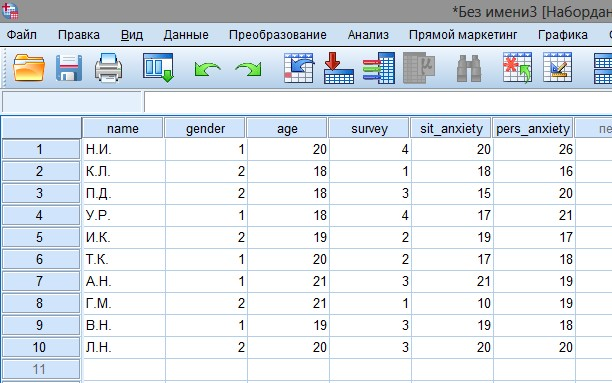
Рис. П1.1(5). Заполненная таблица данных
После того как данные исследования полностью введены в программу, можно приступать к обработке полученных результатов — проводить различные расчеты, строить диаграммы и т.п.
Мы можем сохранить файл данных с помощью соответствующего пункта меню Файл (File), а затем использовать этот и другие файлы для последующей работы.
Далее, мы предлагаем читателю самостоятельно выполнить задание, подобное описанному выше.
Упражнение П1.1(6). В таблице П1.1(7) представлены показатели эмоционального интеллекта в трех группах испытуемых (будем считать, что это интервальная шкала). Введите результаты эксперимента в SPSS.
Таблица П1.1(7). Данные исследования эмоционального интеллекта у испытуемых с истерическим расстройством
| Номер испытуемого | Балл по шкале «Эмоциональная осведомленность» | Балл по шкале «Распознавание эмоций других людей» |
| Здоровые испытуемые | ||
| 1 | 4 | 6 |
| 2 | 6 | 5 |
| 3 | 6 | 3 |
| 4 | 3 | 2 |
| 5 | 4 | 2 |
| Испытуемые с истерическим расстройством | ||
| 6 | 6 | 5 |
| 7 | 7 | 4 |
| 8 | 3 | 5 |
| 9 | 4 | 6 |
| 10 | 3 | 5 |
| Испытуемые с шизодидным расстройством | ||
| 11 | 3 | 4 |
| 12 | 5 | 2 |
| 13 | 2 | 5 |
| 14 | 6 | 3 |
| 15 | 2 | 4 |
Статистическая обработка данных в SPSS
После ввода данных мы можем приступить к их статистическому анализу. Опишем общую схему проведения такого анализа в SPSS. Для вызова различных процедур по статистической обработке данных нужно зайти в меню Анализ (Analyze). В разделах этого меню содержатся пункты по вызову различных процедур обработки данных (рис. П1(8)). При выборе каждого из них появляется соответствующее методу диалоговое окно, в котором необходимо задать параметры проводимого анализа. В каждом виде анализа эти параметры могут быть самыми различными, однако принцип заполнения диалогового окна может быть описан в достаточно общем виде.
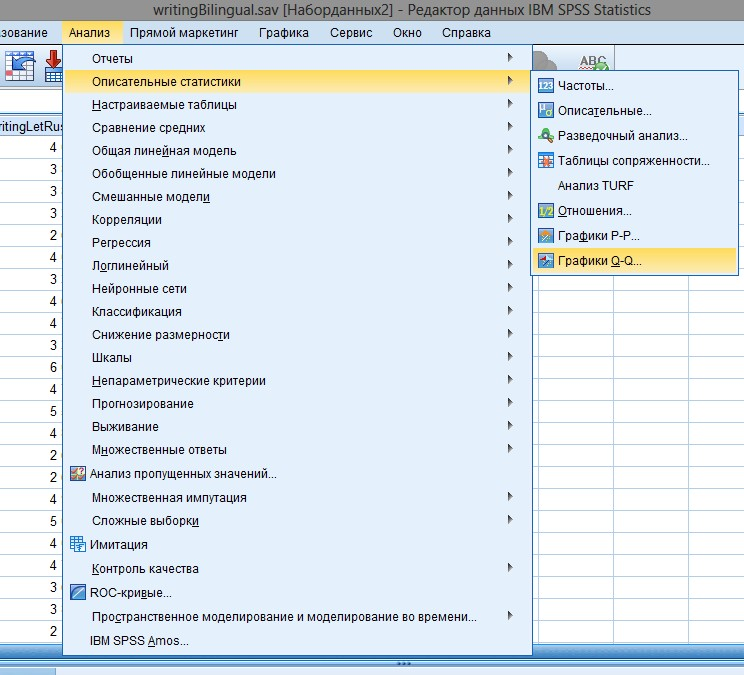
Рис. П1(8). Меню процедур статистического анализа
Количество статистических процедур, реализованных в SPSS, достаточно велико, в рамках нашего учебника мы рассмотрим только некоторую их часть. Основной целью этого приложения является описание техники проведения статистического анализа в SPSS в самом общем виде на материале простого примера.
Пример П1(9). Процедура статистического анализа в SPSS
Рассмотрим общую схему процедуры статистического анализа в SPSS на простом примере — расчете средних значений переменной. В качестве материала мы возьмем данные исследования скорости письма у детей-билингвов младшего школьного возраста. Мы предлагали второклассникам, учащимся в Финско-русской школе города Хельсинки, списать два небольших текста — один на русском, второй на финском языках [3]. Процесс письма регистрировался с помощью графического планшета и затем подвергался обработке и анализу. В частности, оценивалась скорость письма на двух языках, основным показателем было среднее время, затрачиваемое ребенком на написание одной буквы текста. Результаты этого исследования содержатся в файле WritingBilingual.sav. Каждый испытуемый в этом наборе данных характеризуется четырьмя параметрами: идентификационным номером (переменная id), доминантностью русского или финского языка (в зависимости от основного «домашнего» языка, используемого в семье, переменная group), средним временем написания буквы на русском и на финском языках (переменные WritingLetRus и WritingLetFin соответственно).
Первая задача, которую можно решить с помощью SPSS — это расчет описательной статистики [4] времени, затрачиваемого на письмо одной буквы на двух языках. Для этого необходимо войти в пункт Анализ, в нем выбрать пункт Описательные статистики и в подменю выбрать пункт «Описательные». Подобные последовательности действий с пунктами меню мы будем далее обозначать следующим образом:
Анализ — Описательные статистики — Описательные (Analyze — Descriptive statistics — Descriptives).
После этого на экране появится диалоговое окно расчета описательной статистики. Исходный вид окна изображен на рис. П1.1(10).
Рис. П1.1(10). Окно выбора переменных и установки параметров расчета описательной статистики
Как и во всех диалоговых окнах статистических процедур, слева в нем расположен список всех переменных, имеющихся в исходном файле данных. Справа находится поле, в которое необходимо внести переменные, включаемые в анализ, к ним будут применены выбранные статистические процедуры. В нашем случае две переменные — WritingLetRus и WritingLetFin [5]. Перенесем их в поле Переменные (Variables) [6]. Затем мы можем задать те показатели распределения, которые будут рассчитаны для выбранной переменной. Для этого надо нажать на кнопку Параметры (Options). Раскроется дополнительное окно, в котором приводится перечень параметров, расчет которых доступен в рамках данной процедуры (рис. П1.1(11)).
 Рис. П1.1(11). Диалоговое окно для ввода дополнительных параметров процедуры расчета описательной статистики в SPSS
Рис. П1.1(11). Диалоговое окно для ввода дополнительных параметров процедуры расчета описательной статистики в SPSS
Помимо среднего значения, по умолчанию рассчитываются минимальное и максимальное значения выбранных переменных, а также их стандартное отклонение. В рамках этого примера мы предлагаем не рассчитывать стандартное отклонение, минимум и максимум, нужно снять отметки рядом с этими параметрами. Любознательный читатель может выбрать другие параметры, поэкспериментировать с настройками, мы же обсудим наиболее простой вариант.
Такие меню настройки дополнительных параметров есть практически в каждой разновидности статистического анализа, представленного в SPSS. За подробной и исчерпывающей информацией читатель может обратиться к специализированным книгам по SPSS. В рамках этой книги при описании различных расчетов, проводимых в SPSS, мы будем указывать на параметры, имеющие наибольшую важность при базовом освоении темы.
После установки дополнительных настроек можно нажать кнопку Продолжить (Continue), чтобы вернуться к основному диалоговому окну. Далее, для проведения расчетов и получения результата следует нажать кнопку ОК. Результаты расчетов будут выведены в отдельное окно Вывода (Output). Результаты дальнейших расчетов будут выводиться в это же окно в порядке выполнения различных процедур. При необходимости все результаты могут быть сохранены в отдельном файле или импортированы в различные форматы (MsWord, html и т.д.)
Рассмотрим полученные результаты (таблица П1.1(12)).
Таблица П1.1(12). Описательные статистики
| Описательные статистики | ||
| N | Среднее | |
| Average time of writing a letter in Russian | 31 | 3 931.04 |
| Average time of writing a letter in Finnish | 31 | 2 639.32 |
| N валидных (по списку) | 31 | |
В таблице столбец N содержит информацию о количестве испытуемых, далее идут столбцы, содержащие средние выбранных переменных. Как видно из результатов, среднее время написания буквы на русском составило 3931 мс, а на финском — 2639 мс. Таким образом, можно сделать вывод о том, что скорость письма у детей-второклассников на финском оказывается выше скорости письма на русском. Насколько эти различия заметны и отличимы от случайных колебаний можно определить с помощью специальных статистических критериев, о которых идет речь в основной части учебника.
Если нас интересует сравнение средних значений времени написания букв на двух языках у детей с разными доминантными языками и мы хотим оценить, насколько доминантность языка влияет на скорость письма, то необходимо ввести группирующую переменную. В рассматриваемом наборе данных переменная group обозначает принадлежность испытуемого к той или иной группе. Значения группирующих и других так называемых независимых переменных так или иначе контролируются исследователем при организации и проведении исследования. В данном случае мы отбирали детей таким образом, чтобы среди них было примерно равное число детей с доминантным русским и финским языками. Те переменные, на которые могут влиять независимые переменные, называются зависимыми. В нашем примере это среднее время написания буквы.
Рассмотрим, как в SPSS можно рассчитать средние значения для групп испытуемых, определенных с помощью такой группирующей переменной. Для этого надо выбрать в меню последовательность Анализ — Сравнение средних — Средние (Analisys — Compare means — Means). В появившемся диалоговом окне для проведения расчетов необходимо выделить зависимые и независимые переменные. Заполненное окно изображено на рис. П1.1(13).
 Рис. П1.1(13). Заполненное диалоговое окно для сравнения средних
Рис. П1.1(13). Заполненное диалоговое окно для сравнения средних
После нажатия кнопки ОК в окне вывода появляется новая таблица с результатами расчета средних для групп испытуемых (таблица П1.1(14)).
Таблица П1.1(14). Сравнение средних значений двух переменных
| group of bilinguals | Average time of writing a letter in Russian | Average time of writing a letter in Finnish | |
| Russian dominant biliguals | Среднее | 3 530,67 | 2 533,73 |
| N | 16 | 16 | |
| Finish dominant biliguals | Среднее | 4 358,10 | 2 751,94 |
| N | 15 | 15 | |
| Всего | Среднее | 3 931,04 | 2 639,32 |
| N | 31 | 31 | |
Как видно, эта таблица организована несколько сложнее, чем предыдущая. В ней приведены средние значения показателей времени написания буквы как для всей выборки в целом (последние две строчки), так и для двух групп испытуемых по отдельности. Полученные результаты позволяют заметить, что между группами имеются различия в скорости письма, причем доминантность языка приводит ускорению письма: на русском относительно быстро пишут дети с русским доминантным языком, а при письме на финском — наоборот, дети с доминантным финским.
Еще один важный аспект анализа данных, на котором нужно остановиться, описывая основные функции SPSS — это визуализация данных, их графическое отображение. В SPSS есть возможность создавать разнообразные графики, сейчас мы приведем несколько простейших примеров, чтобы у читателя сложилось общее представление о способах графического отображения различных параметров имеющихся данных.
Рассмотрим общий принцип построения диаграмм в SPSS на примере уже описанных данных. Допустим, мы хотим графически отобразить различия во времени написания буквы на двух языках отдельно у детей с доминантным русским и финским языками, т.е. визуализировать приведенную выше таблицу.
Для отображения графиков в SPSS нужно открыть пункт меню Графика (Graphics). Затем можно действовать двумя способами: либо использовать появившийся в сравнительно поздних (начиная с 15-й) версиях конструктор диаграмм (Chart Builder), либо выбрать нужный тип диаграммы в подменю Устаревшие диалоговые окна (Legacy Dialogs). Мы будем описывать наиболее простой и удобный способ в зависимости от задачи.
 Рис. П1.1(15). Диалоговое окно выбора типа столбиковой диаграммы
Рис. П1.1(15). Диалоговое окно выбора типа столбиковой диаграммы
В нашем примере проще нарисовать график распределения возрастов с помощью последовательности Графика — Устаревшие диалоговые окна — Столбцы — Кластеризованные (Legacy Dialogs— Bar — Clastered). В качестве исходных данных зададим Итоги по отдельным переменным (Summaries of separate variables) (рис. П1.1(15)).
После нажатия кнопки Задать (Define) появится диалоговое окно построения диаграммы. Такие окна в SPSS устроены по тому же принципу, что и окна задания параметров статистических процедур: слева приведен список всех переменных, имеющихся в таблице данных, а в правой части — поля для ввода тех переменных, значения которых будут отображены в диаграмме. В данном случае нам необходимо заполнить поле Столбики представляют (Bars Represent) — туда надо перенести две переменные, содержащие показатели времени написания буквы, и поле Категориальная ось (Category Axis) — в него надо внести переменную Group. При переносе переменных в первое поле по умолчанию будет отображаться среднее значение внесенных переменных. При необходимости можно изменить тип рассчитываемой статистики: если нажать кнопку Изменить Статистику (Change Statistics), то появится дополнительное окно, где можно выбрать другие параметры: медиану, стандартное отклонение и др.
После нажатия кнопки ОК в окне вывода появится диаграмма, изображенная на рис. П1.1(16).
 Рис. П1.1(16). Столбиковая диаграмма средних значений времени написания одной буквы на русском и финском языках в двух группах испытуемых
Рис. П1.1(16). Столбиковая диаграмма средних значений времени написания одной буквы на русском и финском языках в двух группах испытуемых
На этом графике достаточно хорошо видно, что время написания буквы на русском меньше в группе детей с доминантным русским языком, а на финском они пишут букву в среднем немного дольше, чем их сверстники с доминантным финским языком. При этом также можно отметить, что в целом время письма на финском меньше, чем на русском.
В данном случае диаграмма, как мы уже говорили, является практически прямым отображением рассчитанной выше таблицы средних, поэтому никакой новой информации из нее мы не извлечем. Однако такое наглядное представление данных в некоторых случаях бывает более удобным. Кроме того, достаточно часто построение диаграмм может дать некоторую дополнительную информацию о данных.
В SPSS можно строить как такие простые графики, так и намного более сложные диаграммы, которые позволяют более полно оценить и проинтерпретировать результаты, получаемые при применении различных статистических критериев. В тексте учебника по мере обсуждения решения тех или иных задач методами математической статистики мы кратко описываем способы построения разнообразных диаграмм средствами SPSS.
Еще одна важная процедура, которая часто используется при обработке данных, — это преобразование переменных и расчет новых параметров на основании имеющихся данных. Так, например, в нашем случае можно рассчитать разность времени написания одной буквы для каждого участника исследования. Для подобного рода расчетов в SPSS надо выбрать последовательность Преобразование — Вычислить переменную (Transform — Compute). После этого появляется диалоговое окно, в котором надо ввести имя новой рассчитываемой переменной в поле Целевая переменная (Target variable), а также формулу вычисления переменной в поле Числовое выражение (Numeric expression). Формула может быть и очень простой, и достаточно сложной, в нее можно включать имеющиеся переменные, а также использовать различные встроенные функции SPSS из списка Функции и специальные переменные (Functions and special variables) в правой части диалогового окна (например, функцию логарифмирования, извлечения квадратного корня, генерации случайных чисел и т.п.). В нашем случае формула расчета будет достаточно проста: нам надо из среднего времени написания буквы на русском вычесть среднее время написания буквы на финском: WritingLetRus − WritingLetFin. Новую переменную можно назвать diffWritingLet. Заполненное окно приведено на рис. П1.1(17).
 Рис. П1.1(17). Диалоговое окно для задания вычисления новой переменной
Рис. П1.1(17). Диалоговое окно для задания вычисления новой переменной
После нажатия кнопки ОК в таблице данных появится новая переменная diffWritingLet, рассчитанная по введенной формуле, ее можно также подвергать статистическому анализу. Таким образом, данная процедура позволяет манипулировать с данными, вводя новые переменные, производные от имеющихся данных.
Упражнение П1.1(18). В файле WritingSkills.sav приведены результаты исследования письма у детей, учащихся первого и второго классов. В качестве экспериментального задания им давали списать небольшой текст. В качестве показателей уровня развития навыка письма регистрировались два показателя — время выполнения заданий в секундах и количество допущенных при письме ошибок. Файл данных, таким образом, содержит три показателя: класс, в котором обучался испытуемый (переменная group), время выполнения задания (переменная time) и количество допущенных ошибок (переменная mistakes).
- Вычислите средние показатели времени списывания и количества ошибок в первом и во втором классе.
- Нарисуйте график изменения этих двух показателей.
В заключение ещё раз подчеркнем, что приведенное в данном учебнике описание не является полным и в целях углубления знания статистического пакета SPSS читатель может обратиться к более специализированным источникам. Перечислим некоторые из них:
Наследов Д.А. IBM SPSS Statistics 20 и AMOS: профессиональный статистический анализ данных. — Издательский дом «Питер», 2012.
Бююль А., Цёфель П. SPSS. Искусство обработки информации, Москва, Diasoft, 2005
Из зарубежных источников мы можем порекомендовать следующие книги:
Field A. Discovering statistics using IBM SPSS statistics. — Sage, 2013.
Brace N., Snelgar R., Kemp R. SPSS for Psychologists. — Palgrave Macmillan, 2012.
[1] Так как в настоящее время в нашей стране одинаково распространены английская и русифицированная версия программы, мы будем приводить русский вариант, а затем, в скобках, давать английский аналог. Перевод на русский язык может меняться в зависимости от версии программы, мы приводим перевод для версии 23. Снимки экрана и таблицы расчетов мы будем давать только в русской версии.
[2] Технически допустимо использование кириллицы в названиях переменных, однако по нашему опыту это в непредсказуемые моменты может приводить к сбоям в выводе результатов. Поэтому мы рекомендуем использовать только латиницу.
[3] Более подробное описание этого исследования и его результатов можно найти, например, в статье: Корнеев А.А., Протасова Е.Ю. Письмо у финско-русских билингвов младшего школьного возраста // Психолингвистические аспекты изучения речевой деятельности. — Т. 13 из Труды Уральского психолингвистического общества. — Уральский государственный педагогический университет Екатеринбург, 2015. — С. 107–122.
[4] Термин «Описательная статистика» в данном случае обозначает, что будут рассчитываться параметры, описывающие распределение данных (в первую очередь, по умолчанию — среднее значение и стандартное отклонение, подробнее см. параграф 3.1)
[5] Обратим внимание, что в общем списке переменных при описании переменной сначала выводится ее метка, введенная нами на русском языке, а затем — собственно, название переменной
[6] В это окно может быть перемещено любое количество имеющихся переменных.